Wireshark基本使用
一个包称为帧更准确
主界面分为4个区域:Display Filter, Packet List, Packet Detail, Packet bytes
减小包的大小
为了减小抓包的数据大小,可以对抓包进行设置
只抓包头。一般能抓到包的大小为1514字节,启用了Jumbo Frame之后可达9000字节以上。大多数情况只需要IP或TCP的头就足够了,具体应用数据都是加密的,一般不需要。
Capture-->Options中设置Limit each packet to为80字节,这样TCP、网络层、数据链路层的信息都有了。如果还要看应用层的信息,可以适当调大到200字节新版本的wireshark中可以在
Capture-->Input中的对应网络接口上设置Snaplen(B)的大小使用Tcpdump抓eth0上的每个包的前80个字节,并把结果保存到tcpdump.cap文件中
tcpdump -i eth0 -s 80 -w /tmp/tcpdump.cap只抓必要的包。让wireshark在抓包时过滤掉不需要的包。在
Capture-->Options-->Input的Capture Filter中输入过滤条件。例如只查看ip为192.168.43.101的包可以输入host 192.168.43.1tcpdump -i eth0 host 192.168.43.1 -w /tmp/tcpdump.cap需要注意如果自己关注的包可能被过滤掉,例如NAT设备把关注的ip地址改掉了
显示过滤 Display Filter
显示过滤可以在主界面上直接输入过滤条件
协议过滤
已经定义好的协议直接输入协议名称即可。对与nfs挂载失败可以使用
portmap || mount进行过滤地址过滤
ip.addr == 192.168.1.104 && tcp.port == 443选择一个包后,可以右键选择follow,再选择一个这个包的协议,可以自动过滤出相关的包。
使用系统右键功能
选择一个关注的数据包后,可以右键后,选择
Prepare as filter,系统会自动提示当前提取的过滤条件,选择select之后,就会填入过滤条件输入框中。Apply as filter则是直接应用这个过滤右键列表中还有其他的filter可以使用
对过滤后的包保存
File -> Export Specified Packets,在对话框中可以选择勾选当前显示的包
技巧
标记数据包,在每个关注的操作之前发一个指定数据长度的ping命令,这样知道这个操作的数据包的范围,只需要找到这些ping的特殊的ip地址和对应的数据段的大小,就把所有的数据包分割开了
1
2
3
4
5ping 192.168.43.1 -n 1 -l 1
操作1执行
ping 192.168.43.1 -n 1 -l 2
操作2执行
ping 192.168.43.1 -n 1 -l 3
设置时间格式
可以通过
View-->Time display format->Date time of Day把时间显示为当前系统的时间,而不出相对的时间如果分析其他时区的包文件,需要把本机的时区改为和当地的时区一致,这样不用再去进行时区换算
设置某种类型包的颜色
可以通过
View-->Coloring Rules设置每一种包的颜色,方便一下找到,例如默认的icmp的颜色为粉色自动分析
Analyze->Expert Information可以看连接建立、重传、reset的统计信息,分析网络性能和连接问题时有用Statistics->Service Response Time可以查看某种协议的响应时间,检测服务器性能时有用Statistics->TCP Stream Graphs可以查看TCP数据传输统计,在Time Sequence中可以查看哪段时间sequence没有变化(水平直线),说明没有数据传输查找
Ctrl+F后可以在搜索条件中选项查找的范围,数据类型,关键字。例如要查找baidu相关的,数据类型选择string,输入baidu查找其他
网络基础
应用层:应用协议
传输层:TCP
网络层:IP
数据链路层:MAC
跨子网通信需要默认网关转发,因此需要先ARP查询默认网关的mac地址,如果一个ARP请求来自另一个子网,也会应答。
MTU:最大传输单元,大多数的网络MTU是1500字节,除非启用了巨帧(Jumbo Frame)达到9000字节。因此TCP不能一次把5000字节的数据之间给网络层传输,否则因为切分导致只能发送1500字节,会认为发送失败要求重传。
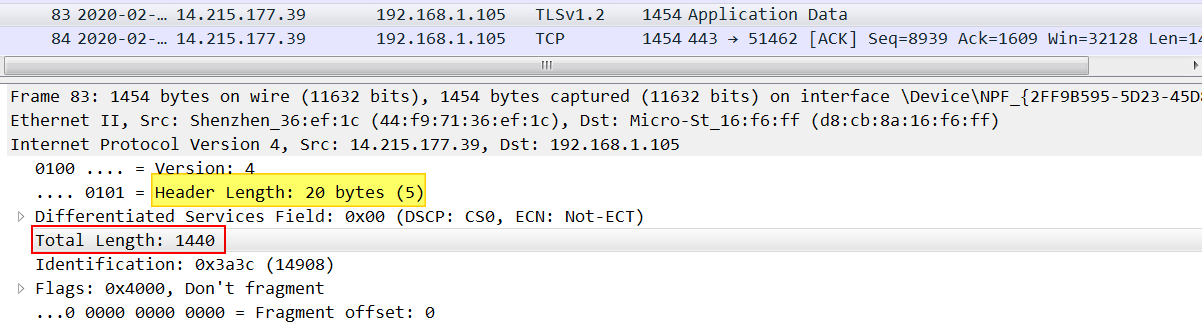
TCP建立连接进行三次握手时,双方会把自己的MSS(Max Segment Size)告诉对方,MSS加上TCP头和IP头的长度,就得到MTU的值。
TCP和IP头的长度都是20字节,客户端给服务端发送的MSS为1460,服务端应答的MSS为1400,因此通信的最小MTU为1400+20+20为1440

实际数据传输中网络层的数据大小为1440字节
TCP
TCP提供可靠有序的数据传输,因此每个数据都有序号,这样接收端可以对数据排序。
TCP中连接的双方各自维护自己的Seq和Ack编号,数据包中的Len的值不包括Tcp包头的长度
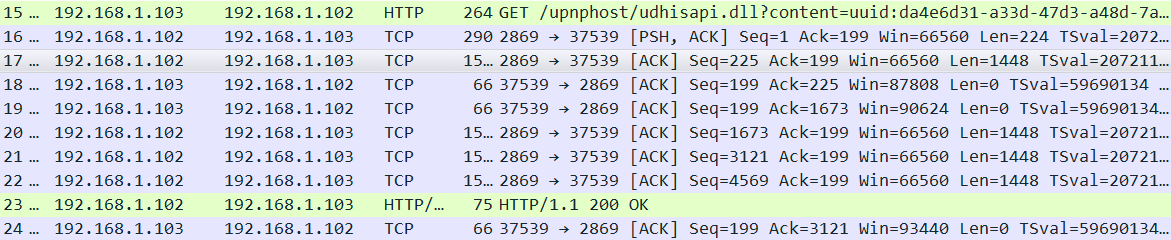
seq的规则:对于一个连接,seq(n) = seq(n-1)+Len(n-1),即上次的seq+上次的Len。例如102发出的17号,seq为102发出的上一个包16号的seq 1 加上 Len 224 所以为225,而102发出的下一个20号包的seq为 17号的seq 225 + Len 1448 = 1673。这样可以知道102一共发送了多少数据,只需要看最后一次的seq+len
ack规则:收到对端的seq+Len。这样可以告诉对端自己一共收到了多少数据。例如18号包应答为16号的seq+16号的Len,即225,19号包应答为17号的seq+17号的Len,即1673,当收到19号包的时候已经累积收了1673字节的数据
- 对收到的数据包按照seq进行排序,并比较相邻的seq和len就知道少了哪些包
例如接收端抓包获取的seq 和len 分别为
| 包号 | 1 | 2 | 3 |
|---|---|---|---|
| seq | 101 | 301 | 401 |
| len | 100 | 100 | 100 |
对于第二个包的seq为301,而它的上一个包的seq+len为101+100=201,说明201这个包没有收到,需要回复ack:201通知对端把seq为201的包再发送一次
TCP的标志
SYN:发起连接请求,由于是双向连接,需要双方都发一次SYN
FIN:请求终止连接,也需要双方都发一次FIN
RST:重置一个连接,或拒绝一个无效请求,一般有这个标志都是有问题
ACK:确认是否有效
PSH: 接收端应用程序需要从TCP缓冲区把数据读走
TCP 三次握手
上面的抓包中,
330号包客户端102发起连接SYN( Synchronize Sequence Numbers ),seq为0 (X),客户端进入SYN_SEND状态
331号包服务器1向客户端发SYN,并对客户端应答ACK,应答ack=1 (X+1),自己的序号seq为0 (Y),服务端进入SYN_RECV状态
332号包客户端102向服务端确认ACK,seq为1(X+1),ack为1(Y+1),客户端和服务端进入ESTABLISHED状态
实际的seq并不是从0开始的,只是wireshark为了方便查看包序号,默认设置了一次连接的相对序号功能。这个功能默认是打开的,可以在Edit->Preference->Protocol->TCP勾选Relative Sequence Number

为什么要三次握手
- 确认双方准备好,如果只有两次握手,服务端收到SYN之后,并给客户端发送SYN就认为连接建立了,但如果这次服务端发送的SYN失败了,它还是认为成功的,直接发送数据D给客户端,而客户端收到数据后,发现seq不匹配,认为连接没有建立,认为数据无效而丢掉数据D,服务端则会认为发送数据一直失败,不断重发数据D
- 明确对端的seq号,才能有序传输
如果客户端发送了一次SYN服务端一直没有应答SYN,此时客户端又发了一次SYN给服务端,而现在服务给第二次应答后,客户端可以依据第二次的服务的应答给服务端应答,从而建立一次正确的连接。如果此时收到服务端应答的第一次SYN,客户端此时的X已经是第二次的X值了,所以判断是一个无效的SYN就可以拒绝服务端对第一次SYN的回复,从而避免错误的连接。
四次挥手
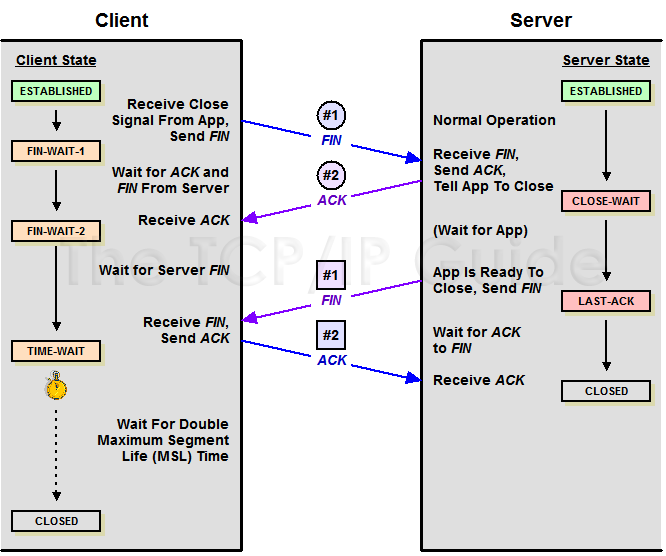
http://www.tcpipguide.com/free/t_TCPConnectionTermination-2.htm
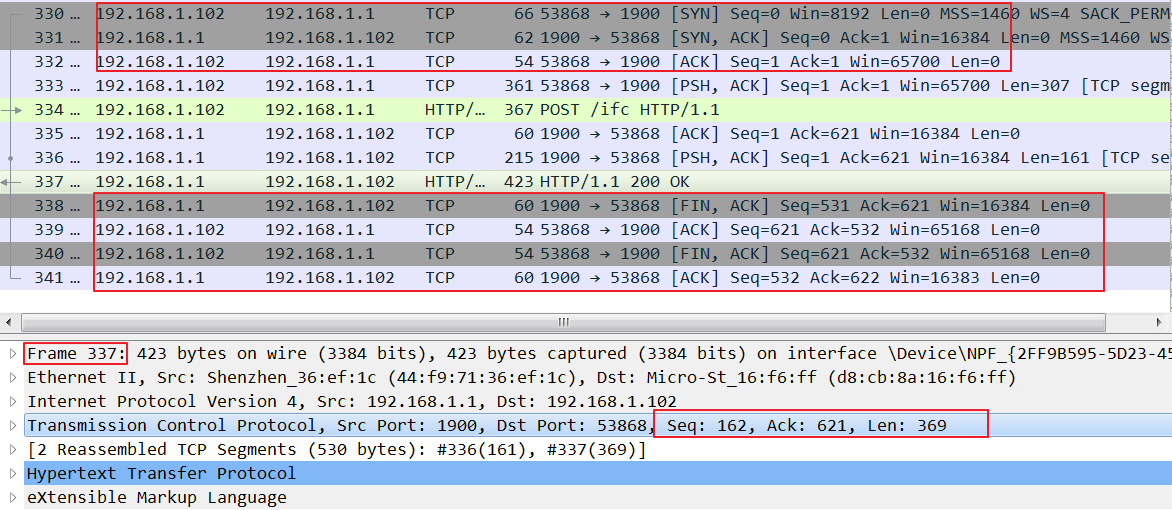
抓包的例子中,是服务端主动发起端口连接,与上图不同
338号包服务端1发起终止连接FIN,seq为162+369=531 (X),ack为对端的seq+len = 621服务端进入FIN_WAIT1状态
339号包客户端102向服务端应答ACK,告诉对端收到了结束连接的请求,应答ack=532 (X+1),自己的序号seq为334号包的Seq+Len= 621(Y),其实也等于服务端应答的ack的值,客户端进入CLOSE WAIT状态,之所以这里没有发FIN是因为此时102可能还有数据给1要发,要等数据发完之后,才能发FIN给1。而服务端收到ACK后进入FIN_WAIT2状态
340号包客户端现在没有要发的数据了,此时给服务端1发送FIN和ACK,这里由于没有数据交互了seq和ack的值没有变化(如果中间102还有给1发过数据,那么这次的seq根据上一个包的seq按照seq的计算规则计算),客户端进入LAST ACK状态
341号包服务端1收到客户端102的FIN之后,说明数据发送完了,可以断开了进入TIME WAIT状态,并给对端应答ACK,seq=X+1 = 532, ack = 对端FIN的seq+1 = 621+1 = 622
客户端102收到ACK后,最终进入CLOSED状态
服务端1在等待2倍MSL( 一个片段在网络中最大的存活时间 )时间后,才进入CLOSED状态
计算规则
对FIN的应答ACK的ack的值为对端的FIN请求的seq+1,即339和341的ack为发送FIN的338和340的seq+1
一次FIN占用1个seq号,因此发送了一次FIN之后,下一包的seq为X+1,即341的seq为338的seq+1
为什么断开连接要四次
在断开连接的发起端发送FIN后,接收端可能还有数据要发送,因此接收端需要先把FIN应答一下,等自己的数据发送完,再给对端发送一个FIN,标识现在可以断开了。因此当一端发送断开连接请求后,没有接收完的数据还是会接收完才会真正断开
为什么要等2MSL
最后一个ACK发出后,对端可能没有收到,从而可能还会发FIN过来,如果直接断开,就不会应答,导致对端一直重复发FIN过来。而2MSL是一个发送和应答的时间,如果等了这么久没有消息,说明对端收到了ACK,就可以断开了。
TCP窗口
一发一答的机制保障数据的可靠性,但是每次一个包的发送,等待应答效率就很低。发送数据时,如果有1000字节的数据,而每个包只能发100个字节,如果1s发送一次数据,每次发送完等待收到应答后,再发送下一个数据,需要发送10s才能发送完所有数据。这样效率太低了,可以不用等上次的应答,直接发送下一个包的数据,例如接收端告诉发送端1s可以处理200个字节,这样发送端1s就发送两个包,这样5s就发完所有数据。而那个200就是接收窗口大小。
一个数据包中的win=8192标识的发送方的接收窗口的大小,这样对端发送数据的时候知道当前可以一次发送多少数据。如果接收时的处理速度跟不上接收数据的速度,缓存就会被占满,最终导致接收窗口的大小为0.
发送窗口由接收窗口和网络因素共同决定大小。发送窗口决定一下子可以最多发送多少字节,MSS是每个包的最大长度
在一个窗口中发出的n个包,不一定就必须对应n个确认包。TCP可以累积起来确认,收到多个包时,可以只确认最后一个。
TCP Window Scale:是为了解决最大窗口数的扩展,TCP头中只有16bit作为窗口大小,因此窗口的大小为65535字节,而技术进步后,这个值太小了,因此又在option中增加了Window Scale,它是2的指数倍。例如窗口大小为128,而window scale是3,则最终的窗口大小为128*(2**3)=128*8=1024
网络拥塞
一次性发送太多数据,就会导致接收端处理不过来,拥塞导致丢包,能导致网络拥塞的数据量称为拥塞点。拥塞情况和数据通过的节点、当时的网络状态相关,因此是动态变化的。
为什么一般很少出现拥塞点?
- windows默认的TCP窗口为64KB,而网络已经进步了这么多,所以不会在窗口范围拥塞
- 大多场景都是小数据传输如网络聊天
- 数据同步传输,就会发一次等一次
- 网络性能提升,出现后很快恢复不易发现
拥塞窗口
由于无法准确定位拥塞点的大小,发送方只能维护一个虚拟的拥塞窗口,并尽量让它接近真实的拥塞点。网络对发送窗口的限制,通过拥塞窗口实现。
- 连接刚建立时,初始拥塞窗口设置为2、3或4个MSS大小
- 如果发出去的包都收到确认,说明可以增大窗口,每收到n个确认,就把窗口增加n个MSS。比如发了2个后收到两个确认,窗口就增大到2+2个,当发了4个都收到时,就增加到4+4个,以2的指数增加。这个过程为慢启动
- 增加到一定值后,增加的量要小点,不能翻倍的增加了,每个往返时间增加了1个MSS,例如发了16个包,全部被确认了,拥塞窗口就增加到17个MSS,一次增加1个。这个过程为拥塞避免。慢启动到拥塞避免的过度点为临界窗口值。
超时重传
发送方发出的数据收不到对应的确认包应答,发送方等待一段时间后,认为包丢失,重新发送一次。从发出原始包到重传这个包的这段时间成为RTO。
发生重传之后,RFC建议重新调整拥塞窗口为1MSS,然后进入慢启动过程。
超时重传性能影响:
- RTO阶段不能发数据,浪费了时间
- 拥塞窗口需要从1MSS重新调整一遍
快速重传
发送数据过程中只有中间的几个包丢失,接收端发现后续的包的seq比预期的大,就会每收一个包,就ack一次期望的seq号,用来提醒发送方重传,当发送方收到3个或以上的重复确认Dup Ack,就认为对应的包丢了,立即重传那个包。用3个来判断是为了避免由于包到达接收端的顺序有差异,导致错误的触发重传。
当在拥塞避免阶段发生快速重传时,RFC 5681认为临界窗口应设置为发送拥塞时还没有被确认的数据量的1/2(但不能小于2个MSS)。然后将拥塞窗口设置为临界窗口的值+3个MSS,继续保持在拥塞避免阶段。而不用向超时重传那样从1个MSS重来一遍。
当发送端有多个包丢掉时,重发的策略有多种:
- 从第一个丢包号开始之后的所有包都重新发一遍
- 接收方收到重传的第一个包后,回复丢的第二个包的序号,发送方根据ack重传,依次把所有丢的包重传完。这个称为NewReno,由RFC 2582和3782定义
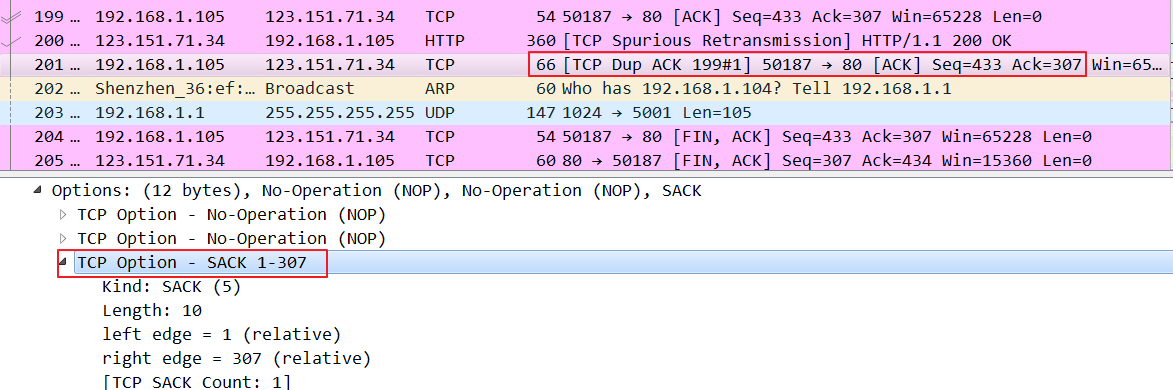
- 接收方通知发送端自己已经收到的包号,同时告诉发送端第一个丢失的包号,发送端根据已经收到和第一个没有收到的包号,把所有没有收到的重发一遍。这种称为Sack方案 RFC2018中定义.Sack中的seq区间为收到的包
结论
- 没有拥塞时,窗口越大,性能越好,可以尽量的增加接收窗口
- 经常发生拥塞,通过限制接收窗口,可间接限制发送窗口,从而减少重传导致的性能损失
- 尽量避免超时重传
- 快速重传影响小,几乎没有等到时间,拥塞窗口减小幅度小
- SACK和NewReno都可以提高重传效率
- 丢包对小文件的影响比大文件严重,小文件可能等不到3个dup ack(总的数据量都没有3个包),所以无法触发快速重传,只能超时重传
Westwood算法
根据接收端应答的ack计算拥塞窗口的大小,收到的确认越多,窗口越大
Vegas算法
根据网络的RTT(往返时间)来决定拥塞窗口,当RTT稳定时,增大拥塞窗口,RTT变大,网络繁忙时主动减小拥塞窗口。
Compound算法
windows中使用两个拥塞窗口,一个用Westwood算法,一个用Vegas算法,真正的拥塞窗口为两者之和。
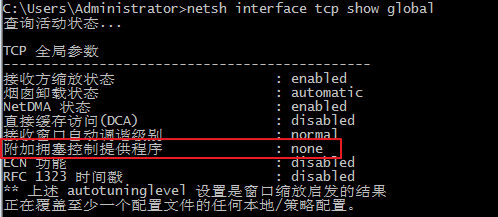
windows可以使用
1 | netsh interface tcp show global # 查看当前的状态,默认为none,即关闭 |
延迟确认
TCP处理交互式场景时,例如远程登录的SSH终端,输入字符,收到一个包之后暂时没有数据要发送给对方,就延迟一段时间再应答确认windows上为200ms。如果在这段时间里有数据发送,把确认包和这个数据在一个包中发回去。这样减轻网络负担。
Nagle算法
在发出去的数据还没有确认之前,又有小数据生成,就把小数据收集起来,凑满一个MSS或等收到确认后再发送。相当于把以后要发送的数据聚集起来一起发。
NFS
Network File System 由SUN设计,用来将网络上的目录挂载到客户端,对于客户端,就像是访问本地磁盘
RFC1813中有详细介绍
NFS对客户端的访问控制是通过IP绑定的,创建共享目录时,可以设置每一个ip的权限
客户端在共享目录中创建文件时可能会用UID作为文件所有者的标识,而不是用户名,而这个UID在别的客户端可能被映射为其他用户,不同的Linux系统客户端用户UID可能是相同的。可以通过抓包查看网络中实际创建的用户信息,在TCP上一层的RPC协议中
portmap进程维护一张进程与端口映射表,他自己的端口号是111,默认值
连接过程
- 客户端通过服务器的portmap进程请求服务端NFS的端口,服务端应答端口号
- 客户端按端口请求连接NFS进程,服务端应答
- 客户端请求mount的端口,服务器应答端口号
- 客户端按返回端口尝试连接服务端mount进程,服务器应答
- 客户端请求挂载/xxx目录,服务端应答file handler给客户端,以便客户端访问文件
客户端访问服务端的文件时,服务端通过文件名先找到file handler来进行后续操作,如果目录中文件过多,获取file handler非常耗时
mount时可以设置每次读的数据大小为512KB
mount -o rsize=524288 192.168.1.101:/tmp/share
默认写数据是异步的async WRITE Call,服务器在真正存盘之前就会应答WRITE Reply从而提高性能,只有COMMIT之后的数据才认为是写成功的。写操作中有UNSTABLE标志。
写操作中FILE_SYNC表示当前为同步sync写,同步写是一写一答,所以不需要COMMIT操作。一些客户端无论设置wsize为多少,每次写的数据都为4KB。
mount时使用noac选项表示让客户端不缓存文件属性,但是会把写操作设置为sync方式,导致效率降低
查问题
如果有问题,可以先用rpcinfo命令获取服务器上的端口列表,再用telnet命令逐个试探进程能否连上
rpcinfo -p 192.168.1.101 | egrep "portmapper|mountd|nfs"
telnet 192.168.1.101 111查看portmap的111端口能否连接上
DNS
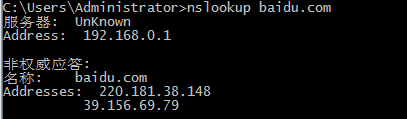
- 使用nslookup默认的UDP查询域名
对应抓包为
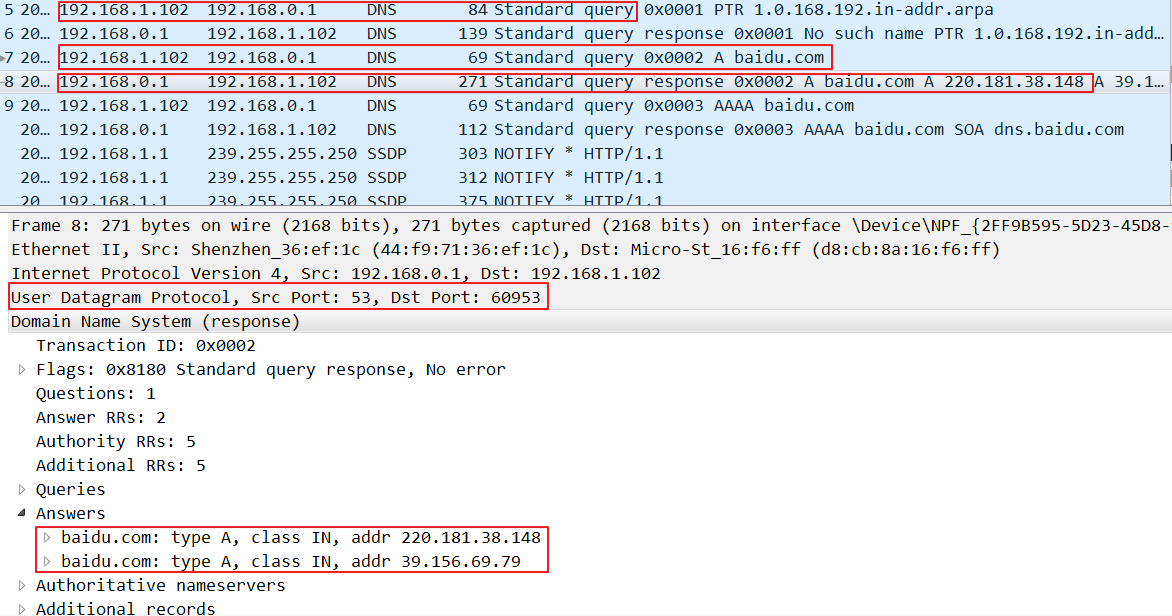
网络环境为两级路由器,主路由器地址为192.168.0.x,次级路由器的ip地址为192.168.1.x,本机ip为192.168.1.102,连接在次级路由器上
由于没有指定服务器的地址,所以会到主路由器上查询,可以看到DNS的传输层为UDP协议
- 使用TCP的DNS
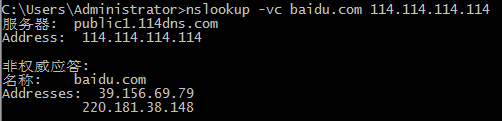
指定-vc选项使用TCP协议,并通过114.114.114.114进行查询
对应抓包为
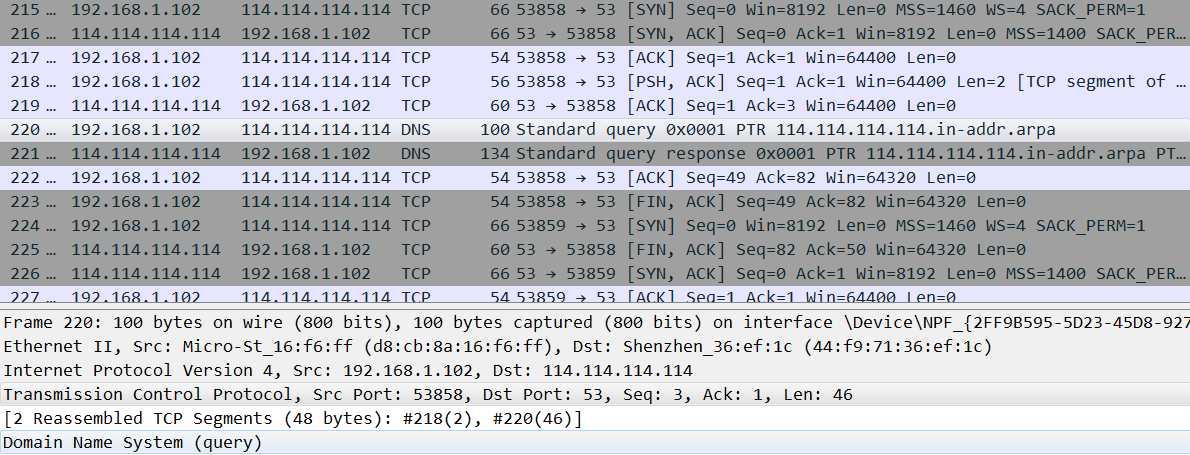
其中215-217是TCP握手过程,220-221对应于查询和应答,223/225为断开连接
A记录 通过域名找到对应的IP地址
PTR记录 从IP解析到域名
nslookup xx.xx.xx.xx可以找到域中的ip对应的名称SRV记录 指向域内的资源
1
2
3nslookup
set tpye=SRV
_ldap._tcp.dc._msdcs.xxx.com #其中xxx.com为域名CNAME记录 别名。即让二级域名指向另一个域名,这样当IP改变只需要改指向的那个www的域名对应的ip,别名指向的是www的域名,不用更改。
域名查询方式
- 递归查询: 从A找到B,B再找C,C再找D,再原路径把D返回给A
- 迭代查询:A依次把B、C、D问一遍,最后找到D
负载均衡
DNS支持循环工作模式(round-robin)。一个网站有10服务器,对应10个IP,每次服务器返回的是其中一个ip,每次查询都按一定的规则切换ip,达到服务器资源的充分利用。
引入问题
- 名字相近的假域名
- DNS服务器地址被恶意修改为假的ip地址
- DNS服务器被攻击
- DNS攻击
UDP
udp的包头一共8个字节,数据量比TCP小,同时不需要建立连接过程
- UDP发送的数据大小直接在网络层分割,接收方收到后组装,这个过程会降低性能
- UDP没有重传机制,丢包由应用层协议处理。如果某个操作过程中,一个包丢失,需要把所有的包全部重传一遍。而TCP只需要重传丢的那个包
- 接收端收到的包中如果有
More Fragments标记说明还有分片的包,如果连续给接收端发这种包,接收端一直收而且无法组装这些分片导致内存耗尽。
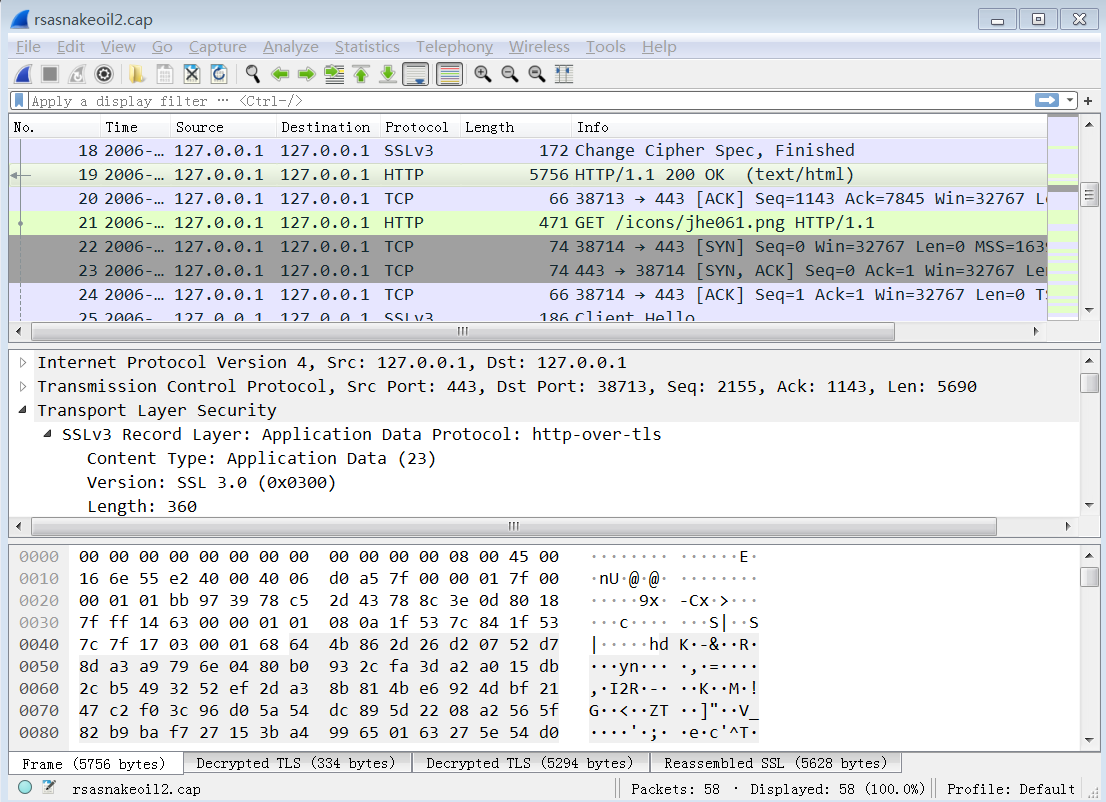
TLS
https://wiki.wireshark.org/TLS
在页面的Example capture file章节有一个TLS的例子可以下载
SampleCaptures#SSL_with_decryption_keys 下载 snakeoil2_070531.tgz 这个文件
使用wireshark打开其中的cap文件,可以看到443端口的通信
第19个包的info显示为Application Data,在包详细信息中显示数据是加密数据
选择要解密的包,右键
Protocol Preference->Open Transport Layer Security Preferences打开RSA key list,编辑加入新的一条解码信息 ip 127.0.0.1, port 443, protocol http, key file选择下载的key文件也可以在
Edit->Prefernces->Protocol->TLS中编辑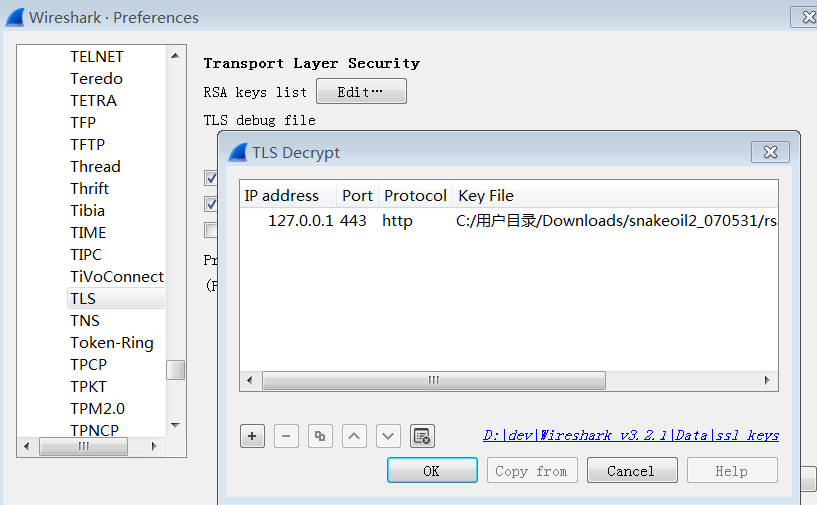
此时19号包显示为HTTP协议,里面的原始数据可以看到
Kerberos
Kerberos是一种身份认证协议,Windows的域中身份认证用到
问题解决
telnet <ip> <port>测试与主机一个端口是否可以连通,如果可以连通,考虑是否因为对端主动拒绝
* 把两个通信的设备连接到简单的网络环境中,排除网络问题
NIC teaming和Large Segment Offload(LSO)可能导致乱序
一般存储设备都是读比写快;对于网络环境,服务端的带宽大,客户端的带宽小。读文件时,大带宽进入小带宽可能导致性能问题
查看实际重传的网络包,分析如果是连续的包都进行了重传,可以考虑打开SACK模式,减少重传包的量
梳理问题的工作原理流程,缩小问题出现在流程中的范围,从而缩小问题范围,模拟问题环境进行复现和解决
tshark
终端上的wireshark版本,Windows安装目录默认有,还有capinfos/editcap。终端处理的数据方便进行导出,生成想要的报表
常用的命令或操作整理为脚本,提高效率
capinfos.exe xx.pcap查看一个包的统计信息tshark -n -q -r xxx.pcap -z "rpc,programs"重看NFS协议的服务响应时间tshark -n -q -r xxx.pcap -z "io.stat.0.tcp.analysis.retransmission"重传统计数据tshark -n -q -r xxx.pcap -z "io.stat.0.tcp.analysis.out_of_order"乱序统计数据tshark -n -q -r xxx.pcap -z "conv,tcp"一个cap文件中所有tcp协议的会话editcap input.cap output.cap -i <second>把包input拆分为second秒长的一个个包文件editcap input.cap output.cap -c <packets per file>把包input拆分为xxx个packets一个的包文件
参考资料
- Wireshark网络分析就是这么简单