RUST Basic
Rust 程序设计语言 - Rust 程序设计语言 简体中文版 (kaisery.github.io)
Install
rustup 是一个管理 Rust 版本和相关工具的命令行工具

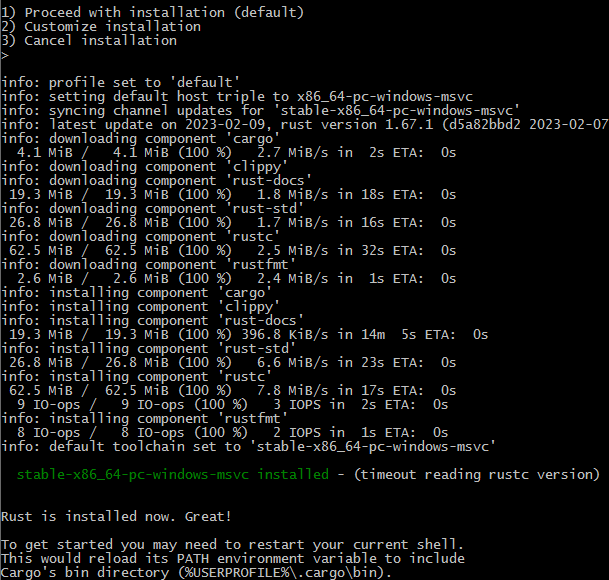
环境变量

更新 $rustup update
安装状态 $rustc --version 输出 rustc 1.67.1 (d5a82bbd2 2023-02-07)
查看文档 rustup doc会自动使用默认浏览器打开安装的离线文档页面
Basic
- 缩进使用4个空格,而不是一个tab
- 调用的宏时,名字后有
!,例如println!("hi human"); - rust中的模块被称为crates
- 使用snake case编程风格,所有字母小写并使用下划线分隔单词
编译
rust和c++一样是预编译静态类型语言
rustc .\main.rs
Cargo
Cargo是rust的构建系统和包管理器,可以自动下载依赖库,在使用rustup安装时一并安装到系统中。
创建一个项目执行
$cargo new cargo_demo
会自动创建一个src目录,一个.gitignore文件和Cargo.toml文件
Cargo使用TOML (Tom’s Obvious, Minimal Language) 格式作为项目配置文件
[package]以[]开始的是一个片段
- 编译工程 在工程目录下执行
cargo build,编译时间很长,生成的文件在target的debug目录下 cargo run编译并直接运行cargo check代码检查cargo build --release编译release版本
依赖
在Cargo.toml的[dependencies]添加依赖库crate,添加一个生成随机数的rand库,版本为0.8.5
1 | [package] |
再次执行build后,会下载所有依赖的库,包括rand依赖的库
编译选项
在Cargo.toml中有三个段和对应的cargo命令相匹配,对应段的设置对对应的命令进行配置。
| 配置段 | 命令 |
|---|---|
| [profile.dev] | cargo build |
| [profile.release] | cargo build –release |
| [profile.test] | cargo test |
例如在编译的release版本时,增加符号信息,可以在[profile.release]段下增加debug信息配置,同时不影响编译优化。 |
1 | [profile.release] |
Cargo.lock
工程中的Cargo.lock文件记录了第一次构建时,所有符合要求的依赖库版本,以后再次构建不会再去找依赖库的版本,方便今后“可重复构建”
如果没有修改工程配置,使用cargo update可以强制更新当前配置文件设置的最新库版本,例如更新到配置文件中指定的最新版本
如果修改了toml的配置文件,执行build时,就会下载最新的库文件。
依赖库离线打包
在工程设置好cargo.toml文件后,在工程的根目录执行cargo vendor,可以把当前工程的依赖库下载到工程根目录下的vendor目录中。
在工程的根目录中新建.cargo目录,并在其中新建config配置文件,配置以下内容让工程使用指定目录的依赖库程序
1 | [source.crates-io] |
把当前工程的整个目录拷贝到其他不能联网的机器,就会使用下载好的依赖库文件,同时也可以提高编译效率,不用每次都重新下载依赖库了。
文档
执行rustup doc --std可以在浏览器中打开本地离线的rust标准库文档
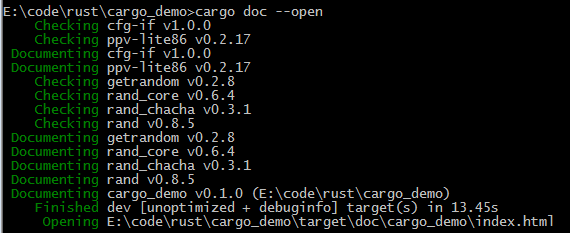
执行cargo doc --open可以构建本地依赖库的文档,并在浏览器中打开

示例程序1
1 | use rand::Rng; |
示例程序2 - web server
Programming Rust 中的示例程序,使用最新的库使用异步方式,不能用书中的源代码
1 | use actix_web::{web, App, HttpResponse, HttpServer}; |
对应的依赖
1 | [dependencies] |
示例程序3 - Mandelbrot Set
依赖
1 | num = "0.4.0" |
这个例子程序以图片中的像素点作为复数平面的点,其中实部为横坐标,虚部为纵坐标,计算每一个像素对应的复数是否在Mandelbrot集合中,如果在集合中这个像素点为纯黑色。
1 | use num::Complex; |
多线程使用时间为9s,不使用多线程需要41s。生成图片如下,这个图片局部放大后的形状都是相似的葫芦形,数学的魅力。


基本语法
变量
变量默认是不可改变的immutable,一旦一个值绑定到了一个变量上,就不能改变这个变量的值。
如果修改一个不可变变量的值,会有这个错误:error[E0384]: cannot assign twice to immutable variable game
不可变变量的好处:
- 并发程序在编译时避免多线程问题?
定义可变变量需要使用mut关键字,虽然可以修改变量的值,但是不能更改变量的数据类型
1 | let mut game = "cod"; |
常量
常量是固定不可变的,使用const关键字,常量可以在任何作用域声明,必须是表达式,不能在运行时计算出值。
1 | const SECONDS_OF_DAY: u32 = 24*60*60; |
隐藏(shadowing)
可以定义一个和之前变量同名的新变量,前一个变量会被隐藏,当第二个变量退出自己的作用域后,变量会恢复第一个变量的值。隐藏是新建了一个变量,并不是改变原来变量的值,和mut完全不同。
1 | let game = "cod"; |
数据类型
标量(scalar)
表示单独的一个数值
- 整型:u8, i8(-128~127), u16, i16, u128, i128, usize, isize和程序架构绑定。变量赋值时,可以使用数据类型来指定类型,例如
56u8指定数据类型为u8,数字之间可以使用下划线_分隔方便读数,如5_600表示5600. - 数字类型表示:十六进制(hex) 0xFF; 八进制(Octal) 0o77; 二进制(binary) 0b1111_0000; 字节(仅能用于u8) b’A’
- 整数溢出:例如给一个u8类型变量赋值256时,debug版本会出现panic错误,release版本会给变量赋值为 0,257赋值为1进行回绕。标准库提供了检查溢出的方法例如
overflowing_* - 浮点型:f32, f64,默认为f64。使用
IEEE-754标准 - 布尔型:bool 两个值
true,false - 字符类型:char 占4个字节,代表一个Unicode标量值。范围
U+0000~U+7DFF和U+E000~U+10FFFF在内的值。
复合类型(Compound types)
将多个值组合成一个类型
元组类型
元组长度固定,一旦声明,长度不能改变。元组中的每一个位置的数据类型可以是不同的。可以使用模式匹配来解构(destructure)元组值。也可以使用元组变量名加.索引的方式获取值。
1 | let tup: (i32, f64, u8) = (500, 3.6, 1); |
没有任何值的元组称作单元(unit),表示空值或空的返回类型。
数组类型
数组中每个元素的数据类型相同,且长度固定。
1 | let food = ["breakfast", "lunch", "supper"]; |
函数
函数声明使用fn关键字开始,每个参数必须声明类型,在函数参数列表后使用->指明函数的返回类型
1 | fn cal_price(val: f64, fac: f64) -> f64 { |
rust的编译器只会推断函数体内变量的类型,函数的参数和返回值的类型必须要声明写出来。
rust的典型函数实现中会用表达式返回函数的返回值,return只在需要在函数体内提前返回值的情况。
表达式
语句(statements) 是执行一些操作但不返回值的指令
表达式(Expressions) 计算并产生一个值,表达式结尾没有分号。
在C++中表达式和语句有明确区分,if或switch这种代码段称为语句, 这样的5*(f-32)/9称为表达式,表达式有值,而语句不会产生值,也不能放在表达式中间。
rust是表达式语言。它的if和match表达式都会产生值。例如可以使用match作为参数
1 | let length = 100; |
所以rust中不需要c++里面的三元运算符(expr1 ? expr2:expr3),rust里面直接使用let表达式就行了。
代码块表达式block expression:对于使用{ }包围的代码块,它的最后一个表达式就是这个代码块的最终值。如果一个代码块的最后一行代码以;结束,它的值为()
控制流
条件表达式
if后跟一个条件,和其他语言类似,这个条件必须返回bool类型的值。if表达式可以给let赋值。如果if语句没有else,那么它必须返回()即最后一行语句要以;结束。否则rust编译器会提示if` expressions without `else` evaluate to `()
1 | let number = 255; |
循环
loop
无条件的循环执行,除非执行了break或程序中断。可以在loop循环的break语句中返回值。
1 | let mut counter = 0; |
循环标签
循环标签可以给一个循环指定一个名字,默认情况下break和continue作用于此时最内层的循环,使用标签可以让他们作用于指定的循环。标签使用‘单引号作为开始.
1 | let mut counter = 0; |
while
while和其他语言相同,条件为true执行循环
1 | while counter < 10 { |
for
使用for x in seq的方式遍历数组
1 | let food = ["breakfast", "lunch", "supper"]; |
匹配
match表达式
由多个分支组成,类似switch语句。每个分支包含一个模式和表达式,表达式以,结尾。
match的每个分支的表达式就是match的返回值,所以分支表达式的数据类型需要相兼容。
match必须用分支覆盖所有的情况,否则会编译错误,可以使用通配符匹配所有其他情况,这个通配符可以看作一个变量名,它匹配所有的其他相同类型的值,我们可以在这个分支的表达式中使用这个匹配变量,也可以使用_匹配任意值,但是我们不会引用它的值,可以看作是default。
模式的匹配是按编写顺序执行,所以不能把通配符分支放在前面,这样后面的分支无法被匹配。
1 | match value { |
在匹配的分支中可以使用模式的部分值。
1 |
|
if let表达式
如果只关系一种匹配的情况,而忽略其他match的分支时,可以使用if let简化match的写法。
1 | let config_max = Some(3u8); |