本地运行AI模型的最简单方法
本地运行AI模型主要分两部分:
- 运行AI模型的后端服务
- 处理用户输入交互的前端界面
LM-Studio
2026-03-17 update:
使用LM-Studio在AMD显卡上运行模型更简单,比Ollama使用方便,对模型更好设置参数,模型更新的也快,需要在程序里面搜索模型,能看到更多的模型,官网看到的模型数量很少,软件里面是直接从hugging-face获取的模型列表,并且官方支持HuggingFace的代理。
- 官方模型下载代理,需要在设置菜单中的General中打开
Use LM Studio's Hugging Face Proxy,不过下载速度没有ollama的快,可以自己使用工具下载gguf的模型,在软件中加载自己下载好的模型文件。 - 在软件左侧工具中的模型搜索中就可以下载想要的模型,并且软件会提示这个模型在本机能否正常运行
- 软件提供自己的API和OpenAI兼容的API接口服务,可以使用LM-studio在后台加载运行模型,在CherryStudio中使用API来访问模型
- 在软件顶部的加载模型列表中,可以手动选择模型加载的参数,例如模型的上下文大小,GPU负载的数量,软件会预估GPU的使用,如果配置的参数超过本机性能,系统会立即提示
- 在软件右侧可以设置这次聊天的模型参数设置例如温度,输出格式,默认的系统提示词等
- 自己使用过程中,觉得和Ollama的速度差不多,只有第一次加载的时候需要时间多一点

Ollama运行AI模型
Ollama安装配置
2026-03-17 新版本Ollama与以前安装有差异
- 在命令行执行
OllamaSetup.exe /DIR="D:\Program\Ollama",后面的DIR参数用来指定Ollama的安装位置 - 可以直接按窗口程序中设置模型的位置
AMD显卡配置
2026-03-17 update:
https://github.com/likelovewant/ollama-for-amd/releases
最新支持AMD的6650XT的版本是0.16.1
HIP支持6650XT的版本是6.4.2,这也是6.x的最后一个版本了,7.x现在还不知道是否支持6650XT
ollama-windows-amd64.7z
HIP 6.4.2
rocm.gfx1032.for.hip.6.4.2.7z
参考https://github.com/patientx/ComfyUI-Zluda 来升级为6.4.2版本
- uninstall 6.2.4 and then delete the ROCm directory from your Program Files folder otherwise there may be problems even after uninstalling.
- Install HIP SDK 6.4.2 from AMD ROCm Hub
- Add entries for
HIP_PATHandHIP_PATH_62to your System Variables (not user variables), both should have this value:C:\Program Files\AMD\ROCm\6.2\ - Check the PATH system variable and ensure that
C:\Program Files\AMD\ROCm\6.4\binis in the list. - Download this addon package from Google Drive (or alternative source)
- Extract the addon package into
C:\Program Files\AMD\ROCm\6.4overwriting files if asked - Get library files for your GPU from rocm.gfx1032.for.hip.6.4.2.7z
- 使用下载的包中的library目录覆盖
C:\Program Files\AMD\ROCm\6.4\bin\rocblas\library - 把下载包中
rocblas.dll文件覆盖到C:\Program Files\AMD\ROCm\6.4\bin目录
- Ollama使用6.4.2的Rocm
解压ollama-windows-amd64.7z到
D:\Program\ollama-windows-amd64\删除
D:\Program\ollama-windows-amd64\lib\ollama\rocm\rocblas\library目录把rocm.gfx1032.for.hip.6.4.2.7z中的library目录替换进去
把rocm.gfx1032.for.hip.6.4.2.7z中的rocblas.dll放到
D:\Program\ollama-windows-amd64\lib\ollama\rocm运行
ollama serve,可以看到日志1
library=ROCm compute=gfx1032 name=ROCm0 description="AMD Radeon RX 6650 XT" libdirs=ollama,rocm driver=60450.10 pci_id=0000:07:00.0 type=discrete total="8.0 GiB" available="7.0 GiB"
ollama run xxx,运行一个模型后,可以在任务管理器中明显看到显存使用增加
以我的电脑AMD 6650 XT 8G显卡为例:
- 下载ollama-windows-amd64.7z ,并解压到
D:\Program Files\ollama-windows-amd64 - 由于Ollama默认不支持 6650XT ,所以需要使用对应显卡内核编译好的的库,例如6650的内核为gfx1032.可以从 https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html 查看
- 在 https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases 下载适用于gfx1032的版本rocm.gfx1032.for.hip.sdk.6.1.2.7z 也可以尝试最新版本
- 下载AMD的HIP SDK https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html ,之前下载的是6.1.2版本,所以SDK也要下载6.1.2版本. HIP SDK可以简单理解为AMD的CUDA平替
- 安装HIP SDK后,把下载的rocm.gfx1032.for.hip.sdk.6.1.2中的文件覆盖
C:\Program Files\AMD\ROCm\6.1\bin目录中的rocblas.dll和C:\Program Files\AMD\ROCm\6.1\bin\rocblas\library目录 - 使用rocm.gfx1032.for.hip.sdk.6.1.2的文件替换ollama安装目录的
rocblas.dll和D:\Program Files\ollama-windows-amd64\lib\ollama\rocblas\library目录 - 在Ollama目录中运行
ollama serve,可以看到输出日志msg="inference compute" id=0 library=rocm variant="" compute=gfx1032 driver=6.2 name="AMD Radeon RX 6650 XT" total="8.0 GiB" available="7.8 GiB"说明可以以显卡来运行ollama中的模型 - 配置ollama的模型默认安装位置(默认C盘用户目录下的
.ollama),新增环境变量OLLAMA_MODELS,值为想要放置模型的目录D:\ollama - 执行
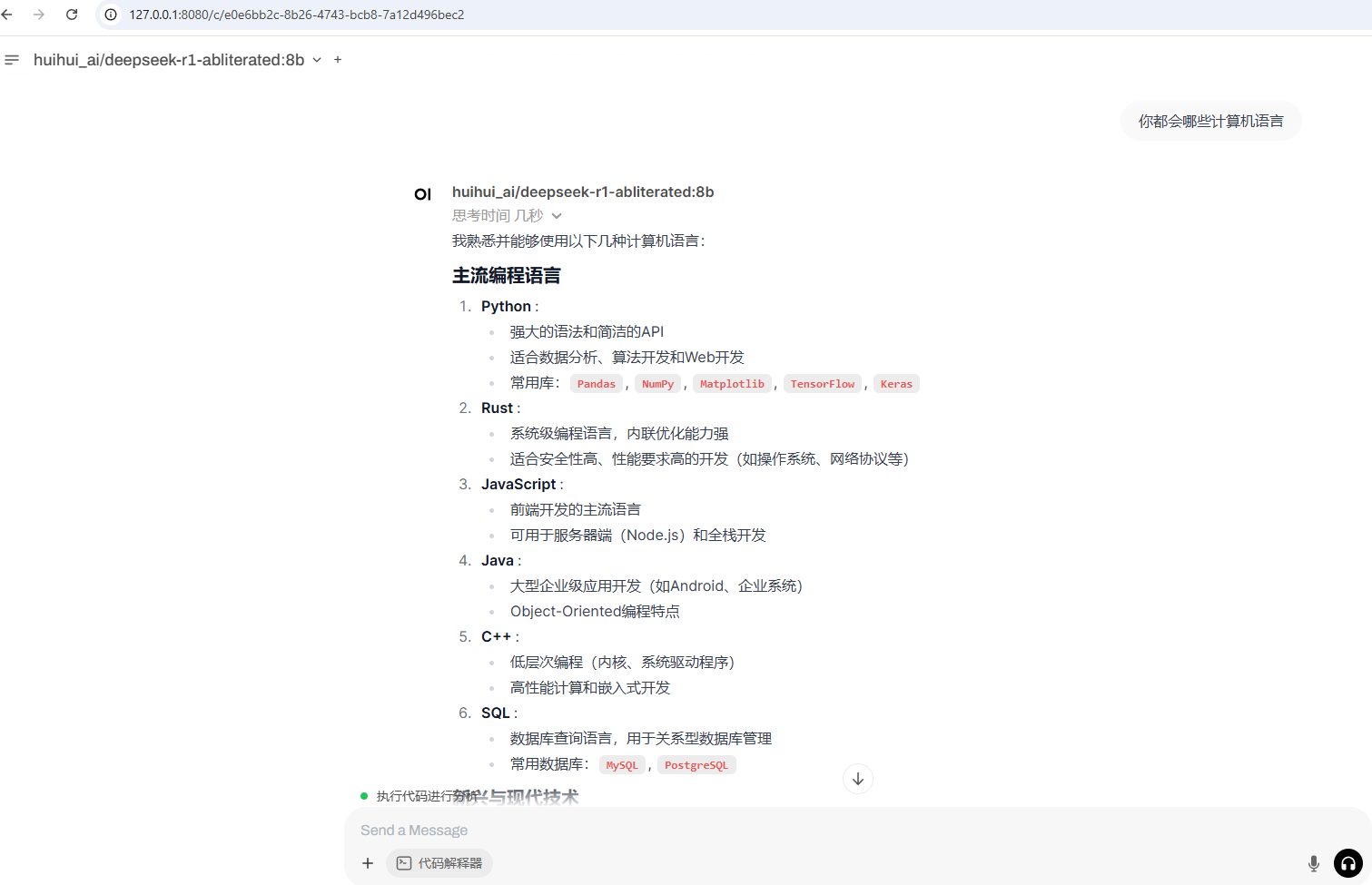
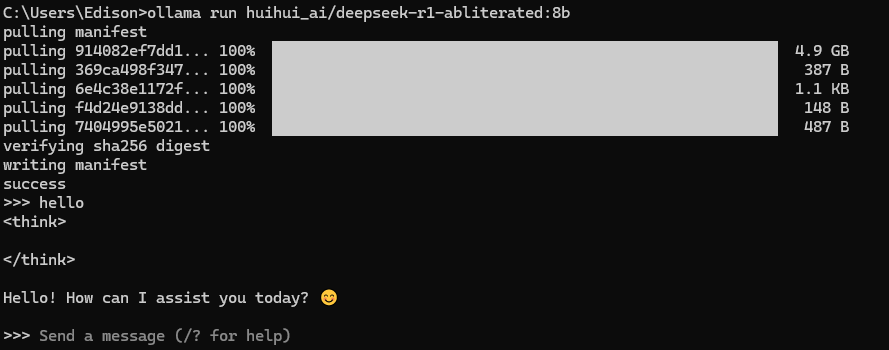
ollama run huihui_ai/deepseek-r1-abliterated:8b安装deepseek-r1-abliterated的模型,也可以在ollama官网安装想用的其他模型,安装完成后,就可以在命令提示符中执行进行对话
对话交互UI
Ollama可以直接和Open-webUI配合使用,默认不需要任何配置。https://github.com/open-webui/open-webui
安装open webUI
- 安装python 3.11以上版本,我使用
Python 3.12.2 (tags/v3.12.2:6abddd9, Feb 6 2024, 21:26:36) [MSC v.1937 64 bit (AMD64)] on win32也是可行的 - 安装
pip install open-webui这个步骤持续时间很长 - 运行
open-webui serve - 浏览器中http://127.0.0.1:8080/ 访问时,提示注册一个本地用户,随便注册就行