AMD GPU使用ComfyUI-Zluda简单图像生成
使用ComfyUI进行间的的文本图像生成,AMD显卡运行pytorch需要额外的配置
AMD显卡Rocm HIP SDK
以我的电脑AMD 6650 XT 8G显卡为例:
从 https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html 查看AMD Radeon表格中可以看到6650XTLLVM的目标环境为gfx1032,默认支持Runtime,但是没有SDK支持
下载AMD的HIP SDK https://www.amd.com/en/developer/resources/rocm-hub/hip-sdk.html ,目前最新版本是6.2.4,HIP SDK可以简单理解为AMD的CUDA平替
在 https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases 下载适用于gfx1032的6.2.4版本rocm.gfx1032.for.hip.sdk.6.2.4.navi21.logic.7z
预编译好的库文件。ROCm是AMD的开源GPU计算软件堆栈,旨在提供一个可移植、高性能的GPU计算平台。
安装HIP SDK后,把下载的rocm.gfx1032.for.hip.sdk.6.2.4.navi21.logic.7z中的文件覆盖
C:\Program Files\AMD\ROCm\6.2\bin目录中的rocblas.dll和C:\Program Files\AMD\ROCm\6.2\bin\rocblas\library目录系统环境变量path中添加
C:\Program Files\AMD\ROCm\6.2\bin目录
升级HIP的版本到6.4.2
2026-03-17 update:
参考https://github.com/patientx/ComfyUI-Zluda 来升级为6.4.2版本
- uninstall 6.2.4 and then delete the ROCm directory from your Program Files folder otherwise there may be problems even after uninstalling.
- Install HIP SDK 6.4.2 from AMD ROCm Hub
- Add entries for
HIP_PATHandHIP_PATH_62to your System Variables (not user variables), both should have this value:C:\Program Files\AMD\ROCm\6.2\ - Check the PATH system variable and ensure that
C:\Program Files\AMD\ROCm\6.4\binis in the list. - Download this addon package from Google Drive (or alternative source)
- Extract the addon package into
C:\Program Files\AMD\ROCm\6.4overwriting files if asked - Get library files for your GPU from rocm.gfx1032.for.hip.6.4.2.7z
- 使用下载的包中的library目录覆盖
C:\Program Files\AMD\ROCm\6.4\bin\rocblas\library - 把下载包中
rocblas.dll文件覆盖到C:\Program Files\AMD\ROCm\6.4\bin目录
升级使用3.9.5版本Zluda
在https://github.com/patientx/ComfyUI-Zluda 有说明更新3.9.5版本,同时patchzluda-n.bat文件中也有注释说明
安装25.5.1以上的驱动,这也是zluda3.9.5更新中说明支持的版本,我选择安装了25.6.1版本
卸载已经安装的HIP SDK,删除目录
C:\Program Files\AMD\ROCm\6.2,因之前替换还有残留的文件 ,下载6.2.4版本 重新安装https://drive.google.com/file/d/1Gvg3hxNEj2Vsd2nQgwadrUEY6dYXy0H9/view?usp=sharing 下载新的补丁
HIP-SDK-extension.zip覆盖到C:\Program Files\AMD\ROCm\6.2目录,不确定这一步是不是必须的,下载的文件有2.12G在 https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases 下载适用于gfx1032的6.2.4版本rocm.gfx1032.for.hip.sdk.6.2.4.navi21.logic.7z 覆盖到
C:\Program Files\AMD\ROCm\6.2\bin目录中的rocblas.dll和C:\Program Files\AMD\ROCm\6.2\bin\rocblas\library目录,否则会提示rocBLAS error: Cannot read C:\Program Files\AMD\ROCm\6.2\bin\/rocblas/library/TensileLibrary.dat: No such file or directory for GPU arch : gfx1032删除
C:\Users\Edison\AppData\Local\ZLUDA\ComputeCache运行根目录的
patchzluda-n.bat,会先卸载之前默认安装的2.3版本的torch,改为安装2.7版本的torch ,我用IDM手动从阿里云下载安装1
2
3
4
5https://mirrors.aliyun.com/pytorch-wheels/cu118/torch-2.7.0+cu118-cp312-cp312-win_amd64.whl
pip install "torch-2.7.0+cu118-cp312-cp312-win_amd64.whl"
#剩下两个比较小,直接从官方安装
pip install torchvision==0.22.0 --index-url https://download.pytorch.org/whl/cu118
pip install torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu118
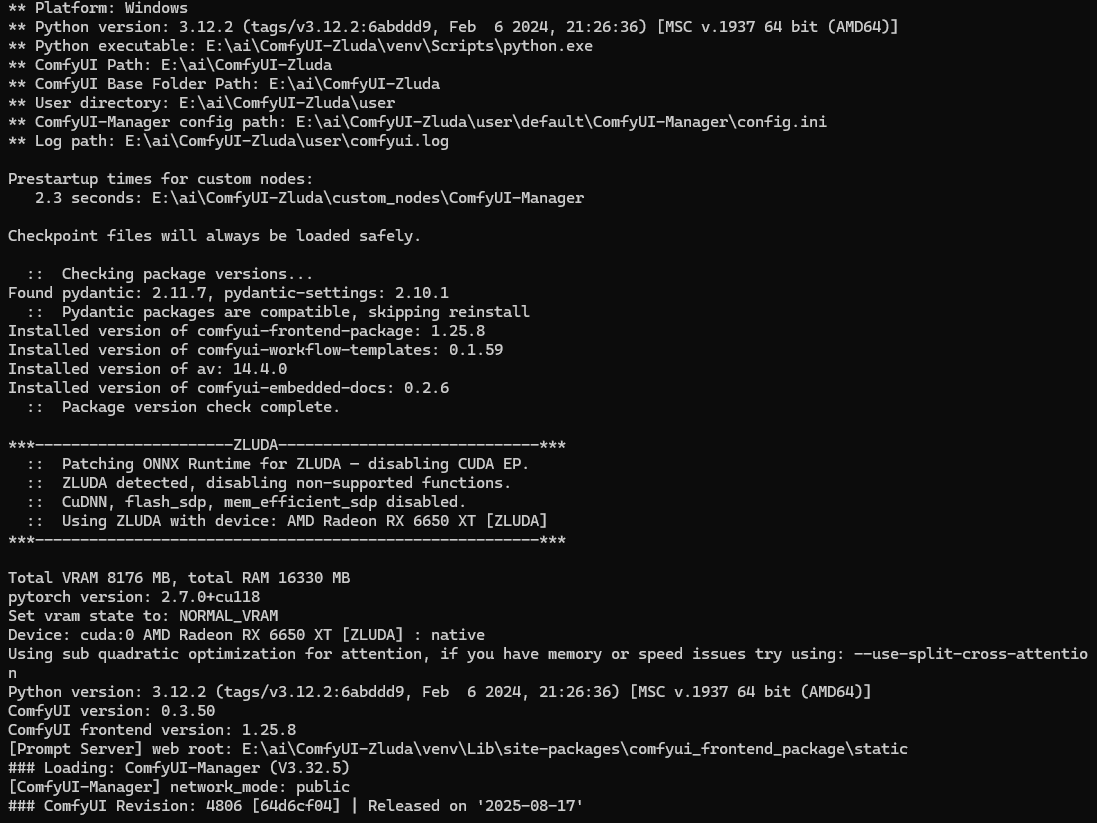
更新后的提示信息,torch版本已经是2.7

新版本的ComfyUI界面也有变化

安装ComfyUI-Zluda
ComfyUI-Zluda项目的网址为https://github.com/patientx/ComfyUI-Zluda
参考项目主页的说明 ,确认安装依赖环境,包括git,python,VC运行时以及AMD HIP这个说明文件很详细的说明了依赖需要的版本和注意事项;python的版本我本机之前安装的是3.12就保持不变,VC运行时重新安装了一遍;AMD HIP 安装的6.2版本
在
E:\ai目录下执行git clone https://github.com/patientx/ComfyUI-Zluda,可以把项目下载到ComfyUI-Zluda目录中进入到ComfyUI-Zluda目录中执行install.bat进行安装,这个过程需要外网连接,同时安装过程中也会提示下载torch文件很大,需要很长时间 。安装过程中会在当前目录中创建venv的目录作为python虚拟环境,安装完成后虚拟环境目录大小为6G。详细安装的内容可以查看install.bat文件。由于安装过程会自动安装ZLUDA补丁,所以不用自己单独下载ZLUDA补丁了。

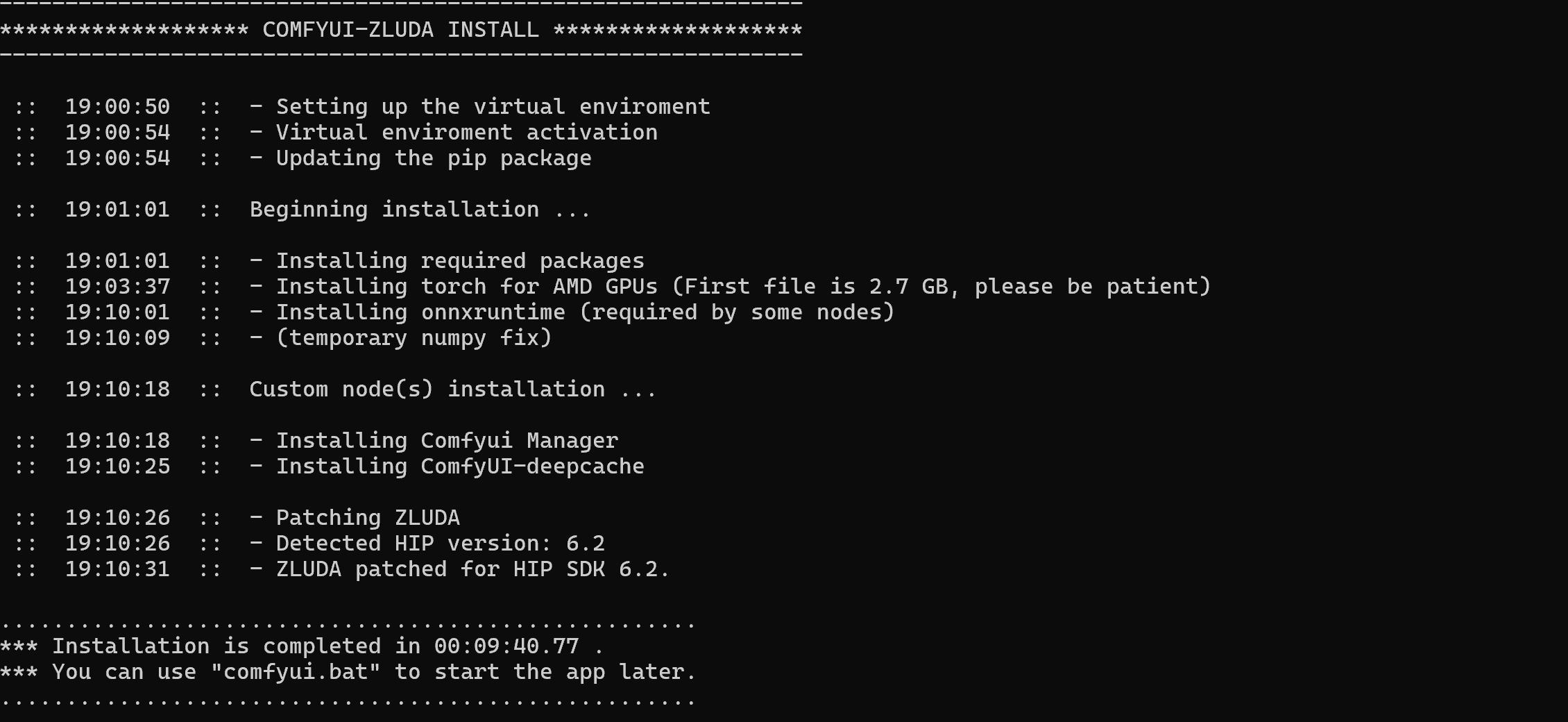
第一次安装完成后,Comfyui会自动运行,并打开浏览器的http://127.0.0.1:8188/
浏览器显示如下:
后台显示:

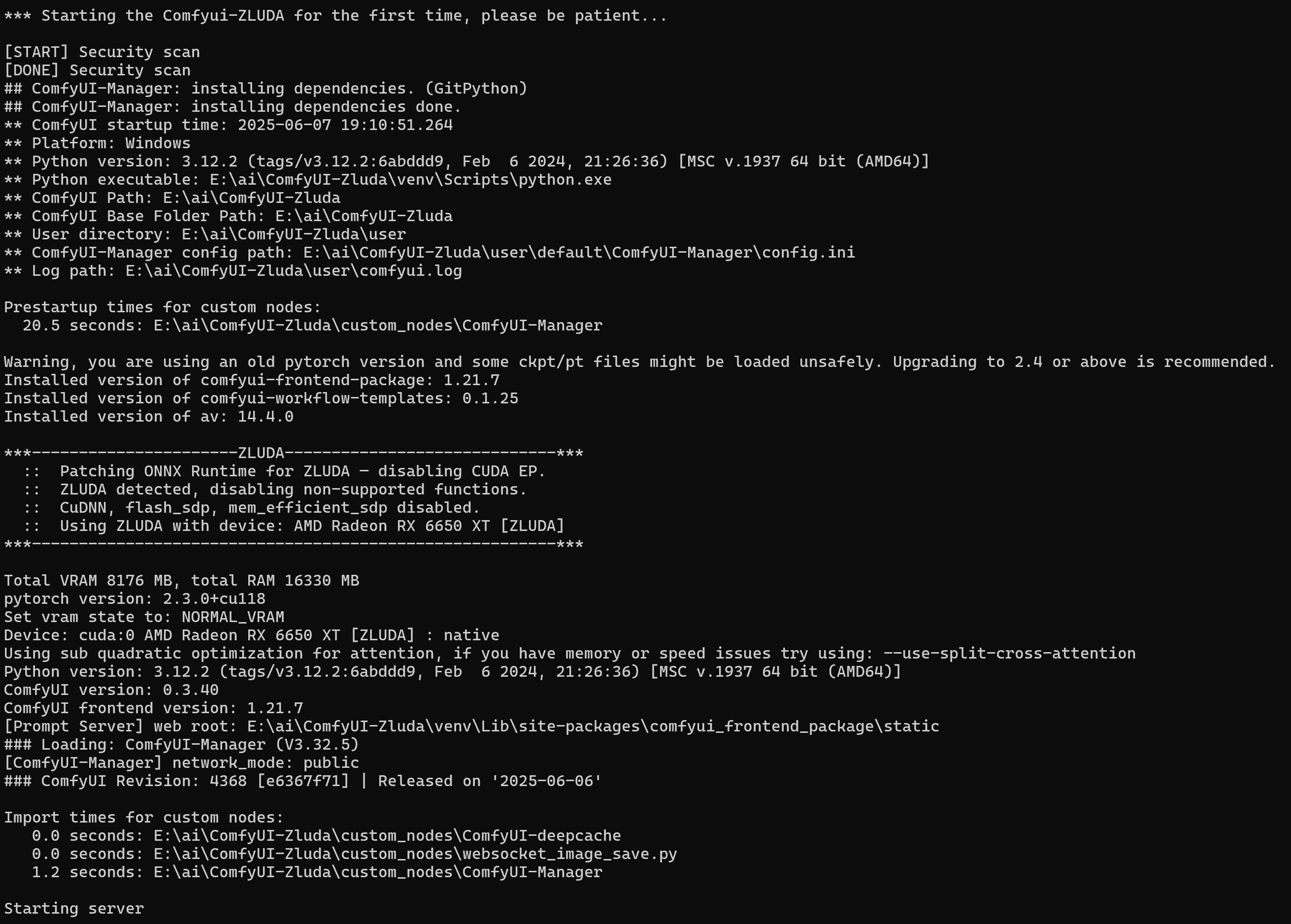
ComfyUI文本生成图像
ComfyUI的使用方法可以到https://comfyui-wiki.com/zh 这个网站学习。
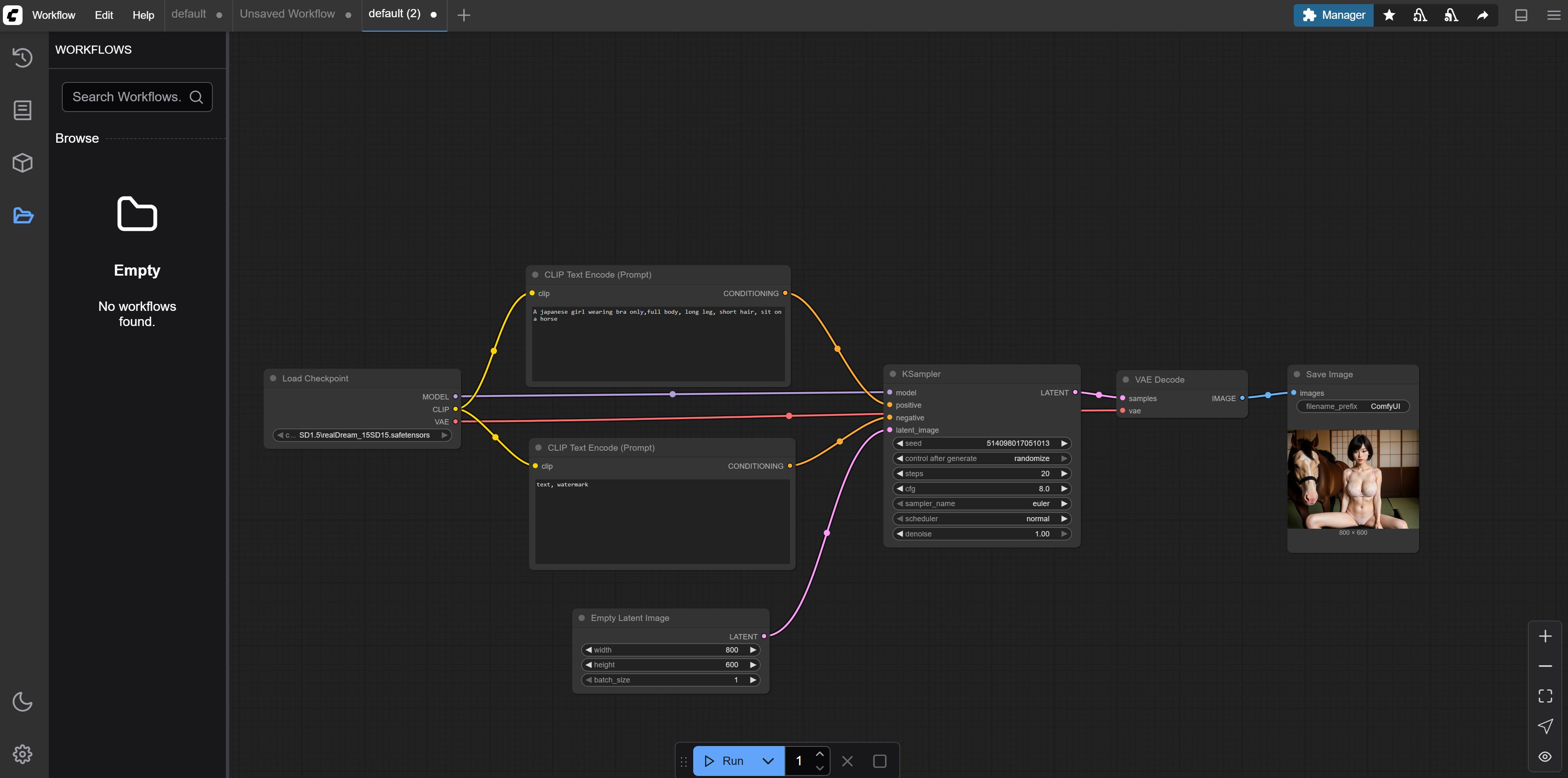
ComfyUI使用工作流的方式来执行生成图像的各个步骤。每个步骤都是一个节点,每个节点有自己的输入和输出,通过输入和输出可以把这些节点连接起来,所有配置好后,执行运行就可以生成图像了。
最简单的方法是用默认提供的基础模板第一个,它包含了最基本文生图的流程。
1. 加载模型
选了基础模板后,会提示没有对应的模型,关掉对话,我们自己下载想要的模型。基本的文生图只需要安装checkpoint对应的模型。
模型的下载可以到https://civitai.com/ 这个网站,这个网站可以按模型类型(checkpoint. lora等),版本(SD的版本),分类排序。例如我下载了这个月排名第一名为Real Dream 的模型realDream_15SD15.safetensors ,模型下载下来的大小为2G
ComfyUI的模型都存放在安装目录的models目录下,这个目录里面又根据模型的类型分别有不同的子目录。
因为下载的是Checkpoint模型,所以把模型文件放在E:\ai\ComfyUI-Zluda\models\checkpoints\SD1.5目录中,SD1.5目录是自己手动创建用来区分SD的版本,以后可能需要下载很多不同的模型。例如我下载了官方的SD1.5模型 v1-5-pruned-emaonly.ckpt文件下载地址,也是放在了checkpoints\SD1.5目录中。
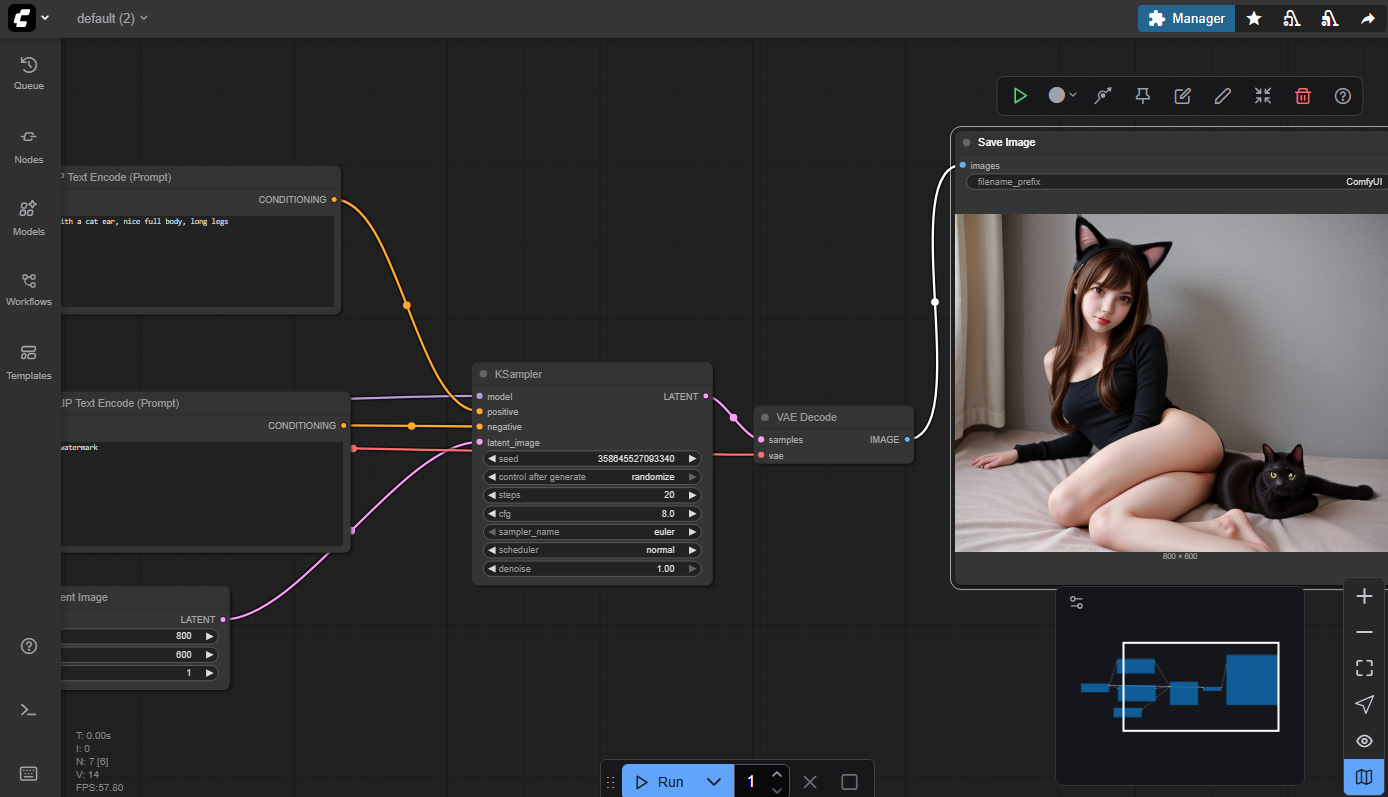
在ComfyUI的Load Checkpoint节点就可以切换不同的checkpoint模型,这个节点的输出是model,clip和vae。
2. 输入提示词
提示词分为正向和负向两种,正向就是图中需要包含的信息,负向就是图像中没有的信息。提示词节点Clip Text Encode(Prompt) 以Checkpoint的Clip作为输入,输出Contidioning。
例如正向提示词可以输入”A japanese girl, full body, long leg, short hair”,负向提示词输入”text, watermark”
3. 设置图片大小
Latent节点可以设置图片的大小,默认是512*512
4. 图像采样KSampler
这个节点把前面所有的输入进行处理生成图像数据,它的输入model为checkpoint的输出,positive和negative分别对应正向和负向提示词,latent_image和设置图像大小的latent连接
5. 合成图像
VAE Decode节点把生成的采样数据生成图片,它的vae和checkpoint的vae连接,最终把图片输出到最后一个节点Save Image。在Save Image节点中可以保存生成的图像。
试用总结
官方模型4G多,网友分享的模型2G,二者比较居然是后者生成的图像质量高很多。官方的1.5模型生成的人物脸都变形了。第一次加载模型使用的时间比较长,后面修改提示词再生成图像就只需要几秒时间。
第一次使用stable diffusion和ComfyUI,很多名词和概念都不明白,但整个过程还是很简单,就像小时候玩积木游戏,一步一步操作,查看输出,满满成就感。

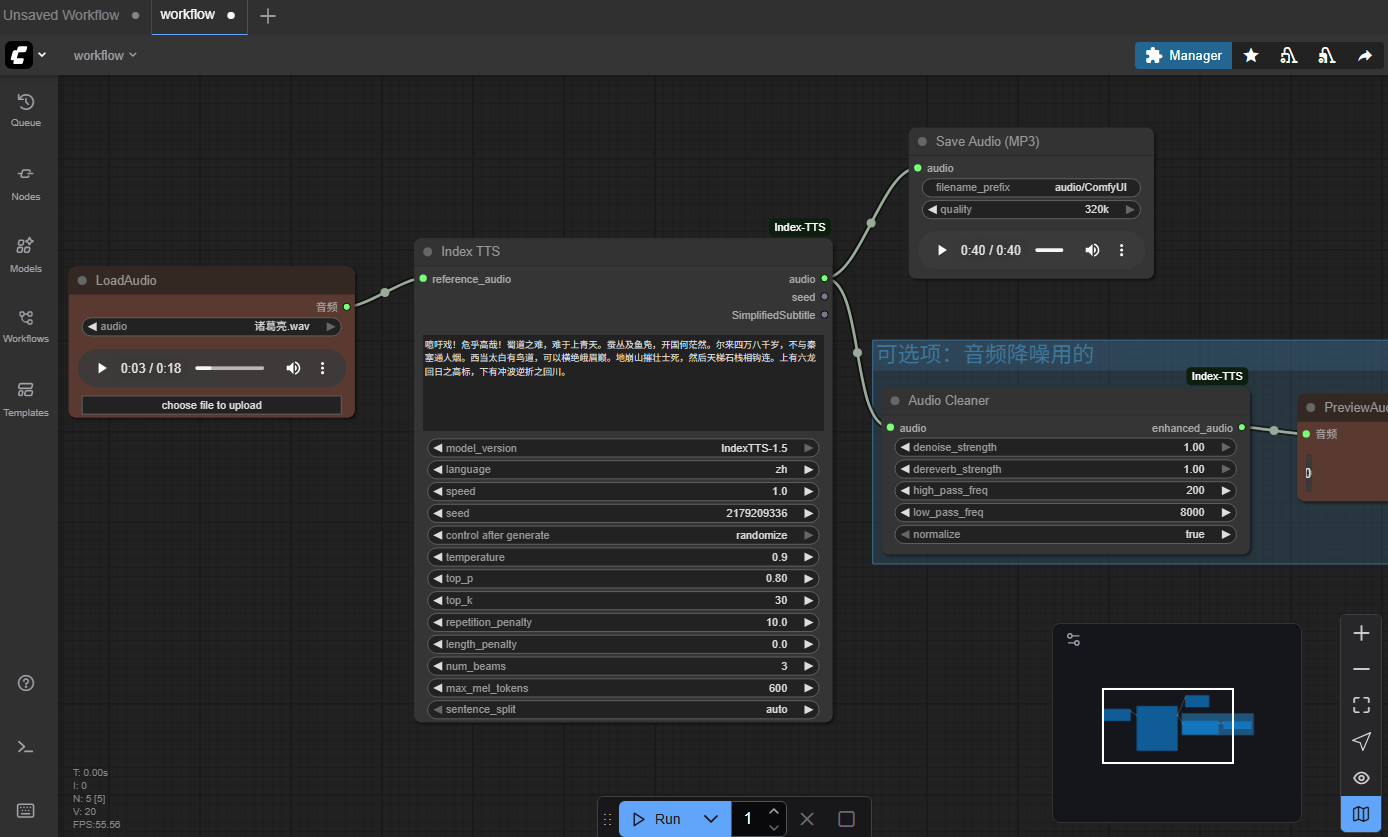
Index-TTS 1.5
插件1. ComfyUI-Index-TTS
在ComfyUI的custom_nodes目录下,执行
git clone https://github.com/chenpipi0807/ComfyUI-Index-TTS.git下载插件代码到ComfyUI-Index-TTS目录中激活ComfyUI的虚拟环境后,执行
pip install -r requirements.txt下载项目依赖pynini和WeTextProcessing这两个因为没有官方windows版本,需要单独安装
https://github.com/SystemPanic/pynini-windows 下载windows编译好的whl文件安装到虚拟环境中,版本为2.1.6.post1
https://pypi.org/project/WeTextProcessing/#WeTextProcessing-1.0.4.1-py3-none-any.whl 下载WeTextProcessing的whl文件,使用不处理依赖的方式安装
pip install WeTextProcessing-1.0.4.1-py3-none-any.whl --no-deps1
2
3
4
5pip install flake8
pip install importlib_resources
pip install pre-commit
pip install pytest
pip install matplotlib在ComfyUI的模型目录下
ComfyUI-Zluda\models执行以下命令,下载模型到IndexTTS-1.5目录中
1 | git lfs install |
- 运行comfyui.bat后,可以在模板的Custom Node下面导入默认的例子工作流
生成40s的音频用35s时间,效果很不错, 声音素材https://drive.google.com/drive/folders/1AyB3egmr0hAKp0CScI0eXJaUdVccArGB

插件2.ComfyUI_IndexTTS
项目地址ComfyUI_IndexTTS,这个项目支持多人对话和之前相比各有特色
作者的另一个网站 https://aiart.website/
这个项目的说明中给出了pynini的安装方法,到https://github.com/billwuhao/pynini-windows-wheels 下载自己对应版本的pynini安装文件 pynini-2.1.6.post1-cp312-cp312-win_amd64.whl,这里编译了Python3.10到3.13的所有版本,虚拟环境中执行
1 | pip install pynini-2.1.6.post1-cp312-cp312-win_amd64.whl |
问题解决
- 2025-08-17 运行comfyui.bat更新最新版本后,无法运行,提示
CUDA initialization: CUDA unknown error查了一下zluda不识别最新的AMD显卡驱动,我因为这条wsl把显卡更新为25.8.1了,因为用的zluda版本3.9.2版本不支持新驱动,所以回退驱动版本25.4.1就可以和以前一样使用了。也可以升级使用最新的3.9.5版本的zluda,这样可以使用新的驱动,顺便把torch版本也升级到2.7。