Cosy Voice 声音克隆
Cosy Voice V2是阿里开源的声音克隆模型,最少只需3秒原始音频,就可以克隆声音,支持中英文和中国部分地区方言。
Miniconda环境安装
Anaconda提供python虚拟环境的功能,与pip不同的是它默认安装了常用的数据科学相关库,所以安装包比较大。除了python的库,它还提供了其他语言的预编译库。
Miniconda也是Anaconda这个组织提供的Anaconda的精简包,它没有图形化的管理界面,只有conda和python需要的基础包,所以安装包小,用户可以根据自己的需要安装合适的包。安装地址https://www.anaconda.com/download/success
下载安装包
国内可以在这个清华镜像下载 miniconda 目前最新的版本是Miniconda3-py313_25.3.1-1-Windows-x86_64.exe里面集成的是3.13版本的python,安装包的大小为87M,安装目录最好选择一个空间大的磁盘,以后虚拟空间会放在这个安装目录的envs目录中,初始安装完成后miniconda3的大小为350M。
安装完成后需要把conda目录添加到系统path环境变量中E:\ProgramData\miniconda3\condabin
配置镜像源
清华大学开源镜像站有说明如何配置 https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
conda的配置文件在windows用户目录的中 C:\Users\Edison\.condarc,修改文件内如下
1 | channels: |
虚拟环境
conda自带python版本不重要,因为创建一个虚拟环境时还可以安装指定的python版本。
- 创建虚拟环境
conda create -n venv -y python=3.10创建一个名称为venv的虚拟环境,python的版本为3.10,默认虚拟环境的目录在conda的安装目录下envs目录中 - 删除虚拟环境
conda remove --name venv --all删除虚拟环境所有包和依赖
Cosy Voice
项目地址 https://github.com/FunAudioLLM/CosyVoice,首页有安装说明。
下载项目代码
在E:\ai目录中执行 git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
官方的安装说明中还指出如果由于网络问题导致安装submodule失败,可以进入CosyVoice的目录中再执行以下命令直到安装成功git submodule update --init --recursive.我是开了外网,不然第一步代码都下载不下来。
配置虚拟环境
创建一个虚拟环境,
conda create -n cosyvoice -y python=3.10官方指南用的3.10,避免折腾还是保持一致。这个语句在哪执行都可以,因为conda默认的虚拟环境都在miniconda3的安装目录下的envs目录中
激活虚拟环境
conda activate cosyvoice
安装依赖和模型
依赖环境的安装要全部在激活的虚拟环境中安装,保持独立的版本,执行目录为下载的cosy voice项目目录。
虚拟环境中安装
(cosyvoice) E:\ai\CosyVoice>conda install -y -c conda-forge pynini==2.1.5安装其他python依赖库
(cosyvoice) E:\ai\CosyVoice>pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com安装过程中可以看到依赖了pytorch2.3.1,一共是2.4G的大小
1
2Collecting torch==2.3.1 (from -r requirements.txt (line 35))
Downloading https://download.pytorch.org/whl/cu121/torch-2.3.1%2Bcu121-cp310-cp310-win_amd64.whl (2423.5 MB)这一步的安装时间比较长,可以先去干别的事情
下载最新的模型
CosyVoice2-0.5B,先进入python解释器,执行官方说明的语句即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28(cosyvoice) E:\ai\CosyVoice>python
Python 3.10.18 | packaged by Anaconda, Inc. | (main, Jun 5 2025, 13:08:55) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>> from modelscope import snapshot_download
>> snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')
Downloading Model to directory: C:\Users\Edison\.cache\modelscope\hub\iic/CosyVoice2-0.5B
Downloading [campplus.onnx]: 100%|████████████████████████████████████████████████| 27.0M/27.0M [00:02<00:00, 10.3MB/s]
Downloading [CosyVoice-BlankEN/config.json]: 100%|████████████████████████████████████| 659/659 [00:00<00:00, 1.59kB/s]
Downloading [configuration.json]: 100%|███████████████████████████████████████████████| 47.0/47.0 [00:00<00:00, 169B/s]
Downloading [cosyvoice2.yaml]: 100%|██████████████████████████████████████████████| 7.16k/7.16k [00:00<00:00, 10.6kB/s]
Downloading [asset/dingding.png]: 100%|████████████████████████████████████████████| 94.1k/94.1k [00:00<00:00, 296kB/s]
Downloading [flow.cache.pt]: 100%|██████████████████████████████████████████████████| 430M/430M [00:38<00:00, 11.7MB/s]
Downloading [flow.decoder.estimator.fp32.onnx]: 100%|███████████████████████████████| 273M/273M [00:24<00:00, 11.6MB/s]
Downloading [flow.encoder.fp16.zip]: 100%|██████████████████████████████████████████| 111M/111M [00:10<00:00, 11.5MB/s]
Downloading [flow.encoder.fp32.zip]: 100%|██████████████████████████████████████████| 183M/183M [00:16<00:00, 11.6MB/s]
Downloading [flow.pt]: 100%|████████████████████████████████████████████████████████| 430M/430M [00:38<00:00, 11.7MB/s]
Downloading [CosyVoice-BlankEN/generation_config.json]: 100%|███████████████████████████| 242/242 [00:00<00:00, 695B/s]
Downloading [hift.pt]: 100%|██████████████████████████████████████████████████████| 79.5M/79.5M [00:07<00:00, 11.2MB/s]
Downloading [llm.pt]: 100%|███████████████████████████████████████████████████████| 1.88G/1.88G [02:51<00:00, 11.8MB/s]
Downloading [CosyVoice-BlankEN/merges.txt]: 100%|█████████████████████████████████| 1.34M/1.34M [00:00<00:00, 3.19MB/s]
Downloading [CosyVoice-BlankEN/model.safetensors]: 100%|████████████████████████████| 942M/942M [01:23<00:00, 11.8MB/s]
Downloading [README.md]: 100%|████████████████████████████████████████████████████| 11.8k/11.8k [00:00<00:00, 40.0kB/s]
Downloading [speech_tokenizer_v2.onnx]: 100%|███████████████████████████████████████| 473M/473M [00:43<00:00, 11.5MB/s]
Downloading [CosyVoice-BlankEN/tokenizer_config.json]: 100%|██████████████████████| 1.26k/1.26k [00:00<00:00, 5.00kB/s]
Downloading [CosyVoice-BlankEN/vocab.json]: 100%|█████████████████████████████████| 2.65M/2.65M [00:00<00:00, 5.30MB/s]
2025-06-08 17:07:26,932 - modelscope - INFO - Creating symbolic link C:\Users\Edison\.cache\modelscope\hub\iic\iic/CosyVoice2-0___5B -> C:\Users\Edison\.cache\modelscope\hub\iic/CosyVoice2-0.5B.
2025-06-08 17:07:26,932 - modelscope - WARNING - Failed to create symbolic link C:\Users\Edison\.cache\modelscope\hub\iic\iic/CosyVoice2-0___5B -> C:\Users\Edison\.cache\modelscope\hub\iic/CosyVoice2-0.5B: [WinError 3] The system cannot find the path specified: 'C:\\Users\\Edison\\.cache\\modelscope\\hub\\iic\\iic\\CosyVoice2-0___5B' -> 'C:\\Users\\Edison\\.cache\\modelscope\\hub\\iic/CosyVoice2-0.5B'
'pretrained_models/CosyVoice2-0.5B'最后有个创建符号链接失败的错误信息,应该没有什么影响,下载下来的
CosyVoice2-0.5B目录大小为4.76G。
运行模型
- CosyVoice2-0.5B模型缺少文件,需要下载spk2info.zip这个压缩包,把压缩包中的spk2info.pt文件放入
CosyVoice\pretrained_models\CosyVoice2-0.5B模型目录中 - 需要安装windows版本的ffmpeg,并把ffmpeg.exe添加到path环境变量中,生成最后一步需要调用ffmpeg进行格式转换,否则会报错
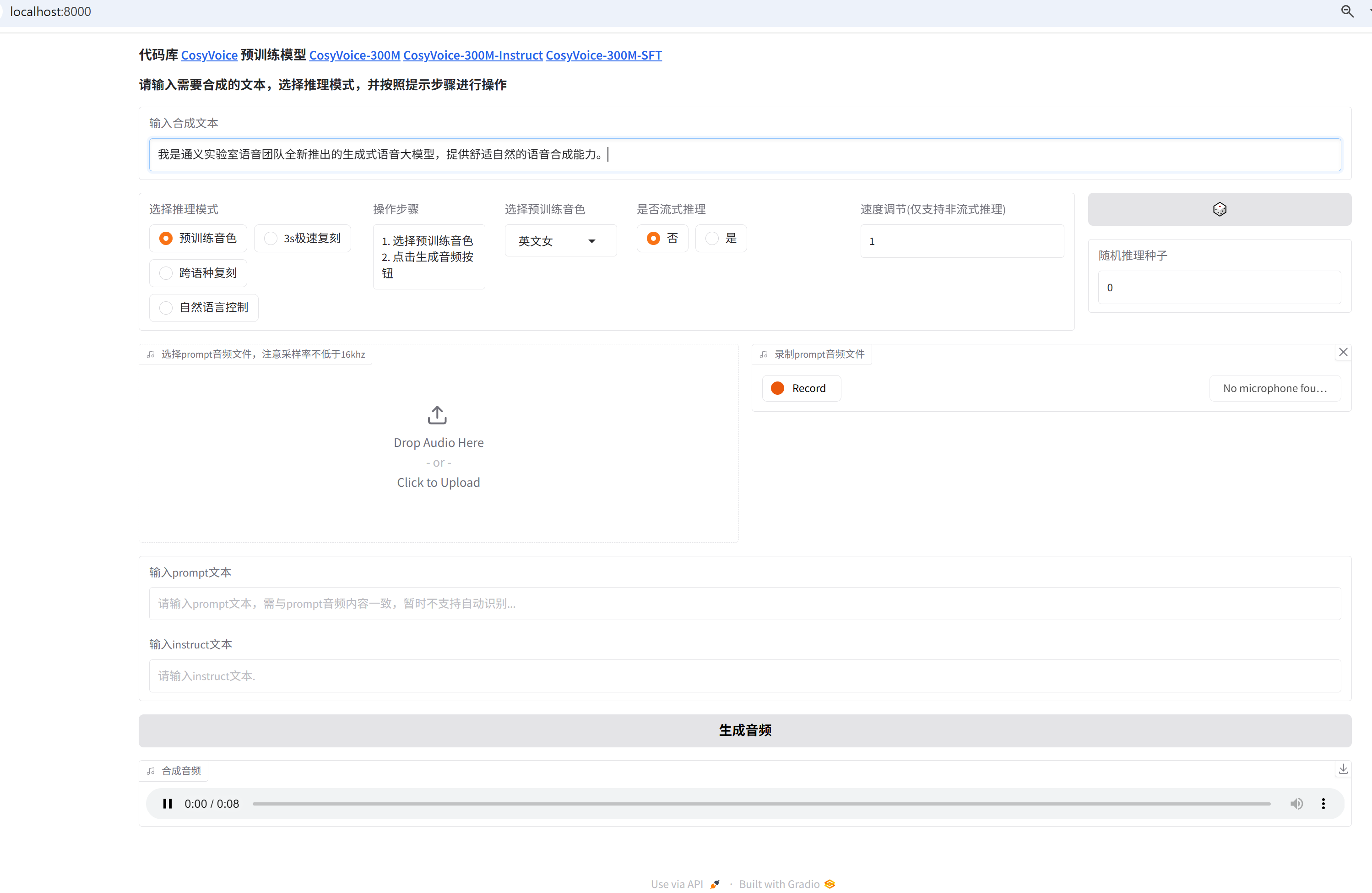
项目根目录的webui.py已经配置好了默认使用的模型CosyVoice2-0.5B,执行python webui.py就可以了,默认运行地址为127.0.0.1:8000。
后台输出如下

webui界面
由于没有适配AMD的GPU,所以是CPU运行,8s的音频需要36s运行。

遇到问题
点击生成音频后,后台报错
1 | File "E:\ProgramData\miniconda3\envs\cosyvoice\lib\subprocess.py", line 1456, in _execute_child |
在官方issue中搜到了这个 系统找不到指定的文件。,按照别人的解决方案从 https://github.com/BtbN/FFmpeg-Builds 下载ffmpeg-master-latest-win64-gpl-shared.zip 解压到任意目录,并把ffmpeg.exe所在的目录添加到系统环境变量path中,需要关闭原来的命令提示窗口(否则新添加的环境变量没识别)重新运行webui.py服务。
WSL的ubuntu24.04环境使用
准备运行环境
miniConda
下载安装miniConda,官方教程是安装home目录,我放在e盘的wsl目录中,最后查了一下wsl使用ext4效率要比共享目录高很多倍,所以程序还是安装到ext4磁盘中比较好。
1 | cd /mnt/e/wsl |
参考这份指南配置中科大的源,之前的清华源访问不了。 vim ~/.condarc,增加以下内容
1 | channels: |
系统其他依赖
提示
No such file or directory: 'ffprobe'需要安装sudo apt-get install ffmpeg提示
failed to import ttsfrd, use wetext instead参看官方指南:
下载模型
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd安装
1
2
3
4cd pretrained_models/CosyVoice-ttsfrd/
unzip resource.zip -d .
pip install ttsfrd_dependency-0.1-py3-none-any.whl
pip install ttsfrd-0.4.2-cp310-cp310-linux_x86_64.whl
安装CosyVoice
下载代码
1
2git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
git submodule update --init --recursive创建虚拟环境和下载依赖
1
2
3conda create -n cosyvoice -y python=3.10
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com下载库的过程中
onnxruntime-gpu==1.18.0这个包不是从国内源下载,即使只有200M也很慢,所以通过过程中的链接地址使用IDM下载下来,再到wsl的虚拟环境中安装这个wheel文件,速度可以快很多。执行
python webui.py运行程序在wsl中
ifconfig查看本地的ip地址为inet 172.26.44.35,在windows中浏览器访问http://172.26.44.35:8000/目前运行时的信息
[WARNING] [real_accelerator.py:162:get_accelerator] Setting accelerator to CPU. If you have GPU or other accelerator, we were unable to detect it.说明系统还是运行的cpu,实际在任务管理器中观察也是cpu在运行。使用以下脚本验证,的确不识别显卡
1
2
3
4
5
6
7
8
9
10
11
12
13
14import torch
def torch_info():
# Print the CUDA version that PyTorch is using
print(f"CUDA version: {torch.version.cuda}")
# Check if CUDA is available
if torch.cuda.is_available():
print("CUDA is available.")
else:
print("CUDA is not available.")
if __name__ == '__main__':
torch_info()