《从零构建大模型》
[美]塞巴斯蒂安·拉施卡
书中资料 https://github.com/rasbt/LLMs-from-scratch
第五章 训练模型(无标签数据)
模型训练过程就是调整模型中的权重参数,大语言模型以及其他深度学习模型的背景下,权重一般指的是学习过程调整的可训练参数。这些权重也被称为权重参数或简单地称为参数。
PyTorch框架中,这些权重存储在线性层中。初始化一个线性层(new_layer = torch.nn.Linear(...))之后,可以通过.weight属性(new_layer.weight)访问其权重。PyTorch允许通过model.parameters()方法直接访问模型的所有可训练参数(包括Weights和Biases)

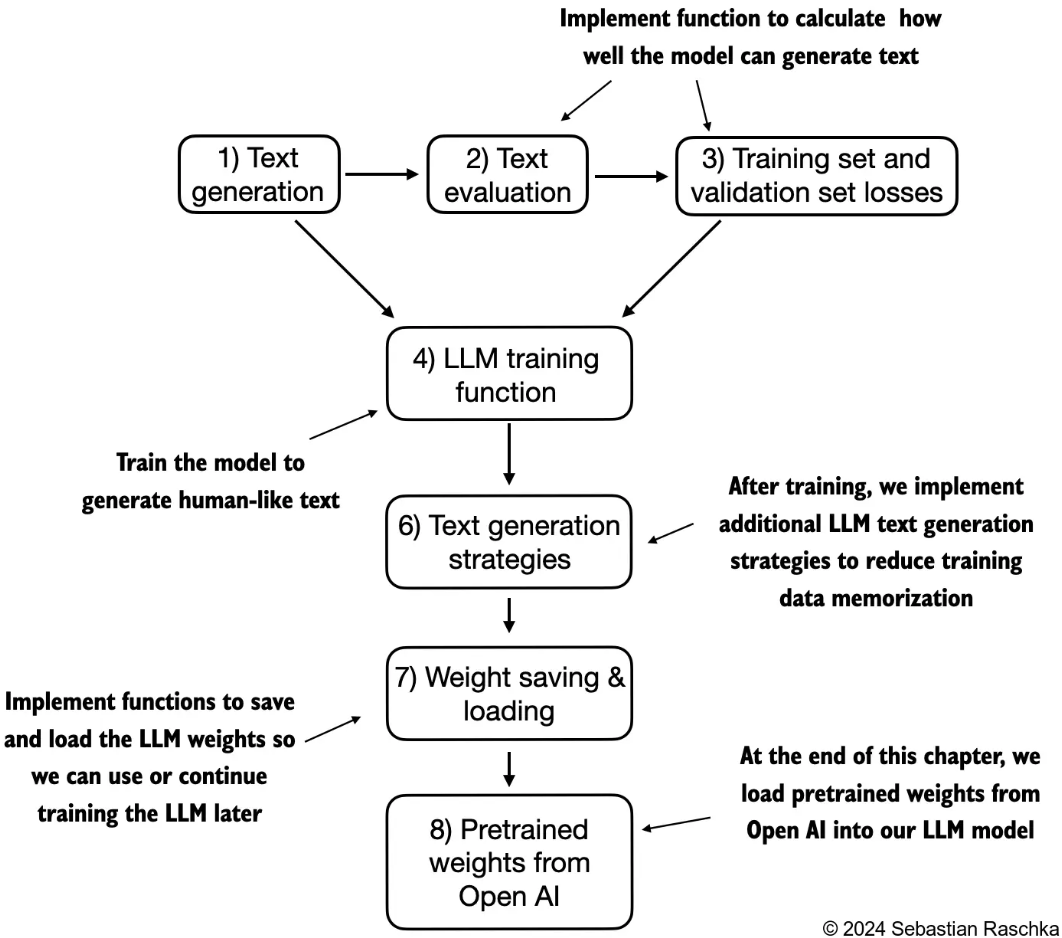
5.1 评估文本生成模型
- 通过计算文本生成损失来对生成的文本质量进行数值评估。
- 文本评估过程的一部分是衡量生成词元与正确预测(目标)之间的偏差程度。目标是对输入数据的复制,但向前移动了一个位置
- 模型训练的目的是增大与正确目标词元ID对应的索引位置的
softmax概率。在训练之前,模型会生成随机的下一个词元的概率向量。模型训练的目标是确保目标词元ID对应的概率值被最大化。
基本评估方法
通过更新模型权重,以便模型为我们想要生成的相应词元ID输出更高的值。权重更新是通过一种称为反向传播的过程完成的,这是训练深度神经网络的标准技术
反向传播需要一个损失函数,它会计算模型的预测输出(在这里是与目标词元ID对应的概率)与实际期望输出之间的差异。这个损失函数衡量的是模型的预测与目标值之间的偏差
- 使用模型得到模型输出logits
- 对logits使用softmax计算词汇表中每个词的概率
- 找出目标词元的对应的概率(也可以称为概率分数,分数越高,越需要被选中)
- 对每一个目标词元的概率进行对数计算,因为数学优化中,使用概率分数的对数比直接处理分数更容易操作
- 通过计算所有概率值的平均值将这些对数概率组合成一个单一分数
- 计算负平均对数概率,我们的目标是通过在训练过程中更新模型的权重,使平均对数概率尽可能接近0。然而,在深度学习中,通常的做法是将负平均对数概率降至0。负平均对数概率就是平均对数概率乘以-1
1 | GPT_CONFIG_124M_TRAIN = { |
交叉熵
在深度学习中,将-10.7940这个负值转换为10.7940的术语称为交叉熵损失。交叉熵损失是一种常用的度量方式,用于衡量两个概率分布之间的差异——通常是标签(在这里是数据集中的词元)的真实分布和模型生成的预测分布(例如,由大语言模型生成的词元概率)之间的差异。
交叉熵函数可以对离散的结果进行度量,类似于给定模型生成的词元概率时目标词元的负平均对数概率。因此,在实践中,“交叉熵”和“负平均对数概率”这两个术语是相关的,且经常可以互换使用。
使用PyTorch内置的cross_entropy函数实现以上3到6的步骤。其参数targets是我们希望大语言模型生成的词元ID,而logits是在进入softmax函数以获取概率分数之前的未经缩放的模型输出。
1 | # 把logits的前两维组合在一起,展平张量 |
困惑度
困惑度通常与交叉熵损失一起用来评估模型在诸如语言建模等任务中的性能。它可以提供一种更易解释的方式来理解模型在预测序列中的下一个词元时的不确定性
困惑度可以衡量模型预测的概率分布与数据集中实际词汇分布的匹配程度。与损失类似,较低的困惑度表明模型的预测更接近实际分布。
困惑度可以通过perplexity = torch.exp(loss)计算得出
1 | perplexity = torch.exp(loss) |
困惑度通常被认为比原始损失值更易于解释,因为它表示模型在每一步中对于有效词汇量的不确定性。在给定的示例中,这意味着模型不确定在词汇表的48 725个词元中应该生成哪个来作为下一个词元。
训练数据集和验证数据集
这里使用Edith Wharton的短篇小说The Verdict作为数据集。通过选择来自公共领域的文本,我们规避知识产权问题。
作者还提供了补充代码来准备一个由60 000多本来自古腾堡计划的公共领域图书组成的更大规模的数据集,并在此基础上训练一个大语言模型(附录D)
数据集准备流程

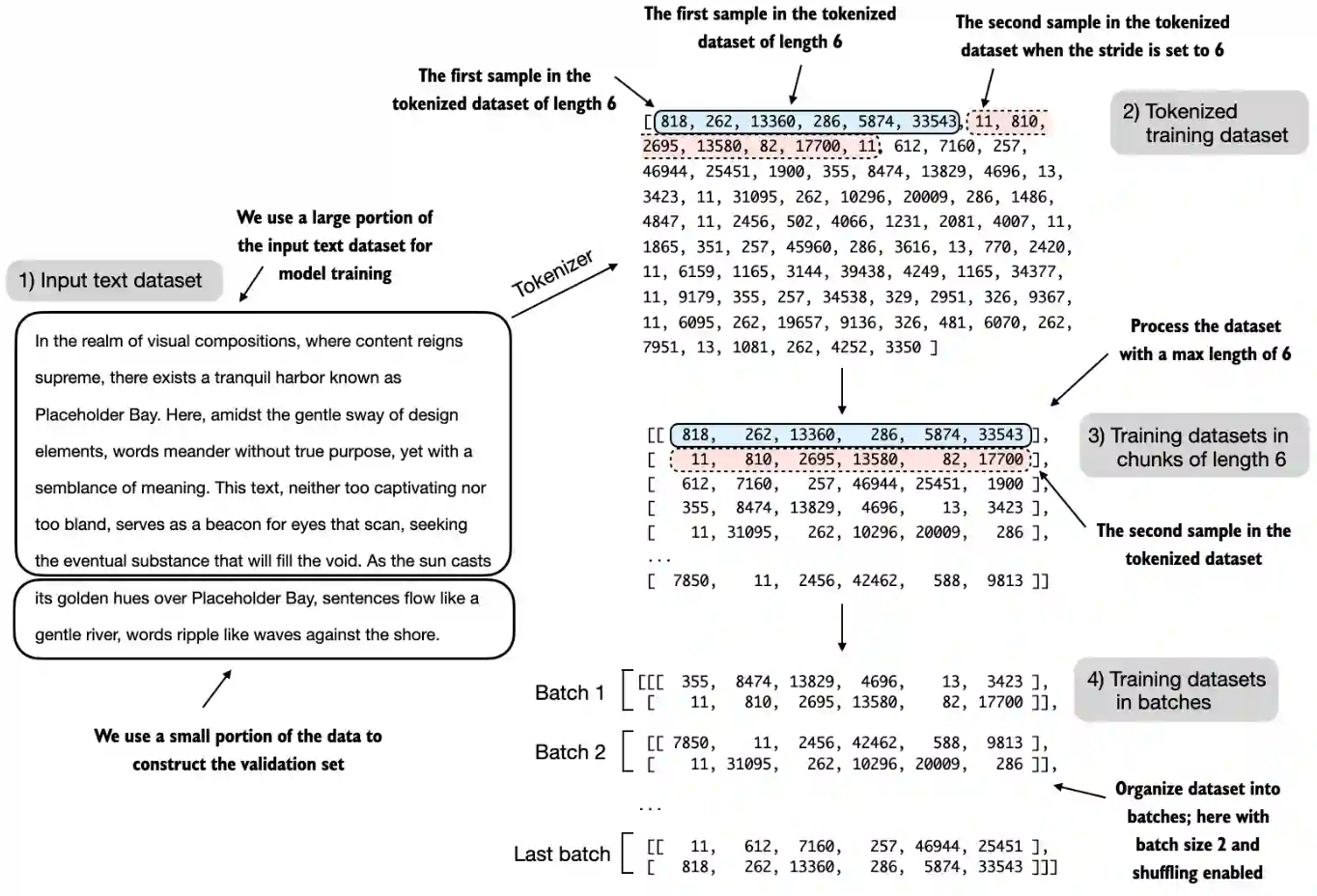
- 为了实现数据拆分和加载,首先定义一个train_ratio,使用90%的数据进行训练,剩余的10%作为验证数据,以便在训练过程中对模型进行评估
- 对文本进行分词(为了简化操作,这里仅显示了训练集)
- 将分词后的文本分成用户指定长度的块(这里是6)在实践中,使用不同长度的输入来训练大语言模型,有助于大语言模型在使用中更好地概括不同类型的输入
- 对行进行重排,并将分块后的文本组织成批次(这里批次大小为2),这些批次可用于进行模型训练。在实践中,更常见的是使用1024或更大的批次大小来训练大语言模型。
- 计算通过训练集加载器和验证集加载器返回的给定批次的交叉熵损失
相关代码实现
从输出可以看到由于没有训练,损失值都很大10.98,最终目标是让损失值为0
1 | def test_data_loss(): |
5.2 训练大语言模型
- 附录D中了解更高级的技术,包括学习率预热、余弦衰减和梯度裁剪
训练的每一个轮次过程有8个步骤,从遍历每个训练轮次开始,处理批次,重置梯度,计算损失和新梯度,更新权重,最后以监控步骤(包括打印损失、生成文本样本等操作)结束

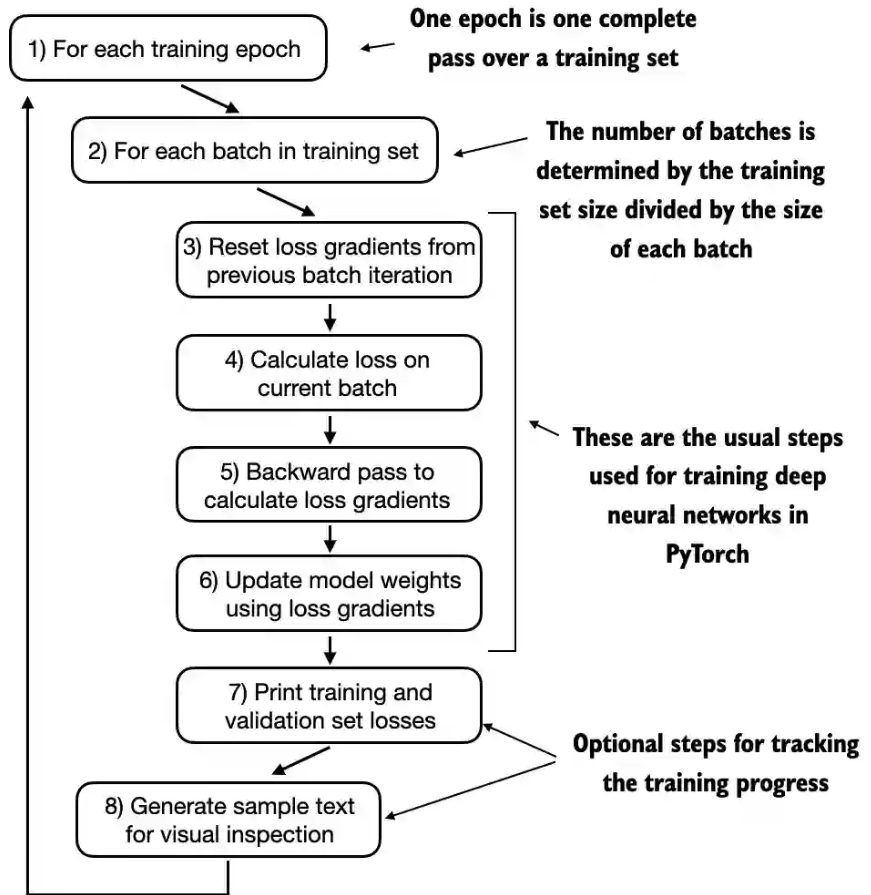
以下train_model_simple函数实现了训练过程:
- 设置模型为训练模式
- 遍历训练集的输入和目标批次依次执行:
- 复位损失梯度
- 计算输入和目标的损失值
- 计算损失梯度
- 使用损失梯度更新权重参数
在训练过程中,训练集损失和验证集损失可用于衡量大语言模型生成的文本质量。代码中的evaluate_model函数在计算训练集和验证集的损失时会确保模型处于评估模式model.eval(),同时会禁用梯度跟踪和Dropout
Adam优化器是训练深度神经网络的一种常见选择。测试程序训练循环中选择了AdamW优化器。AdamW是Adam的一个变体,它改进了权重衰减方法,旨在通过对较大的权重进行惩罚来最小化模型复杂性并防止过拟合AdamW能够实现更有效的正则化和更好的泛化能力。因此,在大语言模型的训练中经常使用AdamW。
1 | def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs, |
1 | Ep 1 (Step 000000): Train loss 9.781, Val loss 9.933 |
从输出的结果看训练集损失有了显著的改善,从9.781的初始值收敛到了0.391。模型的语言能力得到了相当大的提升。在开始阶段,模型只能在起始上下文后添加逗号(Every effort moves you,,,,,,,,,,,,)或重复单词and。在训练结束时,它已经可以生成语法正确的文本。
程序在CPU上运行需要5分钟左右CPU使用率70%左右,使用CUDA,如果zluda第一次编译也需要5分钟,第2次运行只需要0.7分钟,快了很多,CPU的使用率13%,GPU会突然上升一下,显存会用一点。
验证集损失在训练过程中从较高值(9.933)开始逐渐降低。然而,它永远不会像训练集损失那样变得很小,在第10轮之后其值为6.452
训练集损失和验证集损失在第一轮开始改善。然而,损失在第二轮后开始发散。这种发散以及验证集损失远大于训练集损失的事实表明模型对训练数据过拟合。在训练开始阶段,训练集损失和验证集损失急剧下降,这表明模型正在学习。然而,在第二轮之后,训练集损失继续下降,验证集损失则停滞不前。这表明模型仍在学习,但在第二轮之后开始对训练集过拟合
通常,在更大的数据集上训练模型时,只训练一轮是很常见的做法。
5.3 使用PyTorch加载和保存模型权重
保存大语言模型的参数非常重要,这样就不必每次使用它时都重新运行训练。
像AdamW这样的自适应优化器可以为每个模型权重存储额外的参数。AdamW可以使用历史数据动态地调整每个模型参数的学习率。如果没有它,那么优化器就会重置,模型可能学习效果不佳,甚至无法正确收敛,这意味着模型将失去生成连贯文本的能力。
使用torch.save函数保存模型的state_dict,即将每个层映射到其参数的字典和AdamW自适应优化器参数。
1 | torch.save({ |
生成的文件model_and_optimizer.pth大小为1.81 GB (1,952,382,887 bytes)
加载保存的模型参数
1 | def load_model_generate(): |
输出的内容和之前训练最后一步输出的内容完全相同:
1 | Every effort moves you know," was one of the axioms he laid down across the Sevres and silver of an exquisitely appointed luncheon-table, when, on a later day, I had again run over from Monte Carlo; and Mrs. Gis |
5.4 控制随机性的解码策略
文本生成策略(也称为“解码策略”)以生成更具原创性的文本。
在相同的起始上下文(Every effort moves you)中多次运行前面的generate_text_simple函数,输出的文本都是相同的,因为选择下一个词时简单使用了输出的张量中概率最大的词元即torch.argmax()方法的作用,这种方式也叫贪婪解码。
为了生成更多样化的文本,可以用一个从概率分布(这里是大语言模型在每个词元生成步骤为每个词汇条目生成的概率分数)中采样的函数来取代argmax。
假设有一个词汇表为
1 | vocab = { |
模型输出下一个词的logits为
1 | next_token_logits = torch.tensor( |
根据argmax使用概率最大的词,显然词汇表中第4个词Forward的概率最大,因此会选择Forward作为下一个词。
通过对输出的概率向量采样来选择下一个词,而不是直接用概率最大的值。这样每次采样选择的值会有所变化,对于概率大的词元,它被采样选中的概率更大。这个采样可以使用multinomial函数替换argmax函数,multinomial函数按照其概率分数采样下一个词元。换句话说,forward仍然是最可能的词元,大多数时间(但不是每次)都会被multinomial选中,从而实现让每次输出的文本结果可以有所变化。
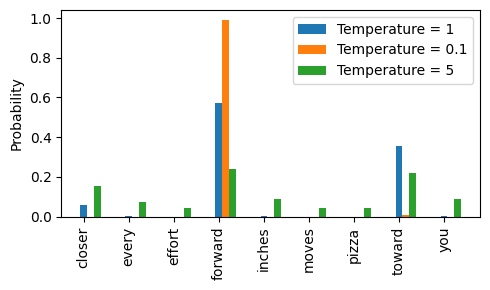
- 温度缩放,可以进一步控制分布和选择过程。温度缩放指的是将logits除以一个大于0的数。温度大于1会导致词元概率更加均匀分布,而小于1的温度将导致更加自信(更尖锐或更陡峭)的分布
1 | def softmax_with_temperature(logits, temperature): |
从图中可以看到温度值越小例如0.1,分布更集中Forward被选中的概率越大。温度值大于1时,所有词元的概率相对更平均一些,也更容易出现无意义的文本。

Top-k采样可以改善文本生成结果。在Top-k采样中,可以将采样的词元限制在前k个最可能的词元上,并通过掩码概率分数的方式来排除其他词元,从而避免出现无意义的预测。Top-k方法用负无穷值-inf替换所有未选择的logits,因此在计算softmax值时,非前k词元的概率分数为0,剩余的概率总和为1
修改后更具多样性的文本生成函数
在对模型输出logits经过Top-k处理后,再使用温度缩放和multinomial函数进行概率采样
1 | def generate(model, idx, max_new_tokens, context_size, temperature=0.0, top_k=None, eos_id=None): |
5.5 从OpenAI加载预训练权重
- 权重指的是存储在PyTorch的Linear层和Embedding层的
.weight属性中的权重参数 - OpenAI最初通过TensorFlow保存了GPT-2的权重,我们需要在Python中安装TensorFlow才能加载这些权重
pip install tensorflow - 可以从https://huggingface.co/rasbt/gpt2-from-scratch-pytorch 下载转换为pytorch的模型数据文件
gpt2-small-124M.pth
https://github.com/rasbt/LLMs-from-scratch/discussions/273
open AI的地址为 https://openaipublic.blob.core.windows.net/gpt-2/models/124M/+文件名,例如https://openaipublic.blob.core.windows.net/gpt-2/models/124M/encoder.json。下载需要科学。
可以从作者GDrive分享的124M GPT-2模型文件下载 https://drive.google.com/drive/folders/1nnI9Bv5KMFXYn7xMC8NT9V6mE2bCS3Dv
一共有7个文件”checkpoint”, “encoder.json”, “hparams.json”, “model.ckpt.data-00000-of-00001”, “model.ckpt.index”, “model.ckpt.meta”, “vocab.bpe”,总大小为476 MB (499,748,864 bytes)。下载的文件放在项目目录\gpt2\124M目录中,根据参数建立不同的目录方便以后切换不同的模型数据。
1 | import os |
settings和params都是Python字典。settings字典存储了大语言模型架构的设置,类似于我们手动定义的GPT_CONFIG_124M。params字典包含实际的权重张量
OpenAI在多头注意力模块的线性层中使用了偏置向量来实现查询矩阵、键矩阵和值矩阵的计算。偏置向量在当前的大语言模型中不常用,因为它们并不提升建模性能,因此不是必要的。然而,由于我们正在使用预训练权重,因此需要匹配相应的设置以保持一致性,并启用这些偏置向量
OpenAI将第一个Transformer块的输出投影层的权重张量存储为params["blocks"][0]["attn"]["c_proj"]["w"]。在我们的实现中,该权重张量对应于gpt.trf_blocks[b].att.out_proj.weight,其中gpt是一个GPTModel实例
1 | # assign函数会在我们尝试匹配两个具有不同维度的张量时提醒我们。此外, |
使用预训练好的权重参数
1 | def test_gpt2_model(): |
Zluda使用cuda
现在用的还是之前ComfyUI-Zluda的环境,pytorch的版本为2.7 cu118版本。
1 | torch 2.7.0+cu118 |
如果直接设置device = torch.device("cuda")使用cuda计算,会出现RuntimeError: CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling cublasLtMatmulAlgoGetHeuristic错误。这时可以
- 使用
torch.device("cpu")使用CPU来运行模型 - 通过设置临时环境变量
set DISABLE_ADDMM_CUDA_LT=1禁用addmm CUDA LT(Lightweight Tensor) 就可以正常使用
使用zluda编译的程序第一次回特别慢,因为它需要把cuda代码转换为AMD支持Rocm的应用接口。第2次运行就会块很多。只要程序代码不变,就不需要重新编译。