《从零构建大模型》
[美]塞巴斯蒂安·拉施卡
书中资料 https://github.com/rasbt/LLMs-from-scratch
第六章 针对分类微调
6.1 微调分类
微调语言模型最常见的方法是指令微调和分类微调
指令微调涉及使用特定的指令数据对一组任务进行训练,以提高语言模型理解和执行自然语言提示词中描述的任务的能力。指令微调提升了模型基于特定用户指令理解和生成响应的能力。指令微调最适合处理需要应对多种任务的模型,这些任务依赖于复杂的用户指令。通过指令微调,可以提升模型的灵活性和交互质量。
分类微调指模型被训练来识别一组特定的类别标签,比如在消息中过滤“垃圾消息”和“非垃圾消息”。这类任务的例子不仅限于大语言模型和电子邮件过滤,还包括从图像中识别不同的植物种类,将新闻文章分类为体育、政治、科技等主题,以及在医学影像中区分良性肿瘤和恶性肿瘤
经过分类微调的模型只能预测它在训练过程中遇到的类别,即训练过程中的目标值。例如,它可以判断某条内容是“垃圾消息”还是“非垃圾消息”,但它不能对输入文本进行其他分析或说明。分类微调更适合需要将数据精确分类为预定义类别的任务,比如情感分析或垃圾消息检测。分类微调所需的数据和计算资源较少,但它的应用范围局限于模型所训练的特定类别
- 对大语言模型进行分类微调的三阶段过程:
1. 准备数据集 1. 模型设置 1. 模型的微调和应用
6.2 准备数据集
数据预处理
数据集来源https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip 下载的数据集文件名为SMSSpamCollection,文件中内容每一行为一个样本,spam表示垃圾短信,后面跟4个空格长度的tab和短信内容;ham表示正常短信,后面跟1个空格长度的tab和短信内容,整个文件有5574行
1 | spam SMS. ac Sptv: The New Jersey Devils and the Detroit Red Wings play Ice Hockey. Correct or Incorrect? End? Reply END SPTV |
原始文件中正常短信有4827条,垃圾短信有747条,为简单起见,使用一个较小的数据集(这将有助于更快地微调大语言模型),并对数据集进行下采样,使得每个类别包含747个实例,这样两个分类数据输入数量相同。处理类别不平衡的方法有很多,但这些内容超出了本书的范畴。如果你对处理不平衡数据的方法感兴趣,可以在附录B中找到更多信息
将数据集分成3部分:70%用于训练,10%用于验证,20%用于测试。这些比例在机器学习中很常见,用于训练、调整和评估模型。
1 | import pandas as pd |
三个数据集分别存储到一个文件中,以后可以复用。保存后的”train.csv”文件内容前3行如下:
1 | Label,Text |
创建数据加载器
训练输入的短信数据每一行的长度都不相同,这里将所有消息填充到数据集中最长消息的长度或批次长度。确保每个输入张量的大小相同对于接下来实现数据批处理是必要的。
在把输入的单词转换为词元ID的过程中,如果一个输入长度小于最长消息长度,可以将”<|endoftext|>”对应的词元ID(50256)填充到到编码的文本消息中,使所有的输入长度相同。
可以像处理文本数据那样来实例化数据加载器。只是这里的目标是类别标签,而不是文本中的下一个词元。如果我们选择批次大小为8,则每个批次将包含8个长度为120的训练样本以及每个样本对应的类别标签。即8行短信内容为一个批次,每行输入为短信文本内容,训练目标数据为数据标签label 0或1
数据集总的数量为747*2 = 1494,按0.7比例做为训练集,则有1045条训练集数据,每个批次大小为8,对应的批次数量为1045/8 = 130
1 | from torch.utils.data import Dataset |
6.3 模型设置
初始化带有预训练权重的模型
和第5章一样加载预训练好的GPT2模型,使用之前的测试文本输出模型的结果,确认模型加载成功
1 | def init_model_for_spam(): |
添加分类头
我们将GPT2模型的最后的线性输出层(该输出层会将768个隐藏单元输出映射到一张包含50 257个词汇的词汇表中)替换为一个较小的输出层,该输出层会映射到两个类别:0(“非垃圾消息”)和1(“垃圾消息”)
通常令输出节点的数量与类别数量相匹配。例如,对于一个三分类问题(比如将新闻文章分类为“科技”“体育”或“政治”),我们将使用3个输出节点,以此类推
由于模型已经经过了预训练,因此不需要微调所有的模型层。在基于神经网络的语言模型中,较低层通常捕捉基本的语言结构和语义,适用于广泛的任务和数据集,最后几层(靠近输出的层)更侧重于捕捉细微的语言模式和特定任务的特征。因此,只微调最后几层通常就足以将模型适应到新任务。同时,仅微调少量层在计算上也更加高效。
GPT模型包含12个重复的Transformer块。除了输出层,我们还将最终层归一化和最后一个Transformer块设置为可训练。其余11个Transformer块和嵌入层则保持为不可训练
- 为了使模型准备好进行分类微调,我们首先冻结模型,即将所有层设为不可训练
- 替换输出层
(model.out_head)这个新的model.out_head输出层的requires_grad属性默认设置为True,这意味着它是模型中唯一在训练过程中会被更新的层 - 在实验中发现,微调额外的层可以显著提升模型的预测性能。(有关详细信息,请参见附录B。)所以将最后一个Transformer块和连接该块到输出层的最终层归一化模块设置为可训练
对于每一个输入词元,都会有一个输出向量与之对应,输入节点个数和输出的节点个数相同,例如[1, 4]的输入Do you have time,它的输出为[1, 4, 2]

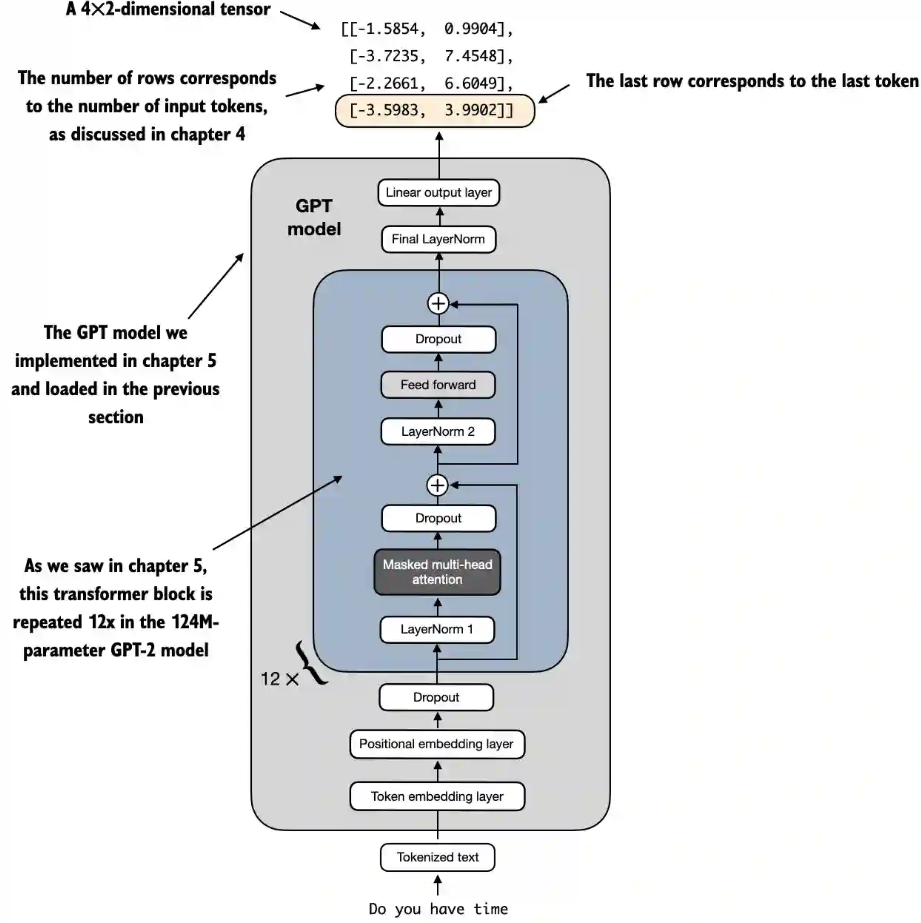
- 为什么只需要关注最后一个输入词元的结果?
根据因果注意力掩码的概念,每个词元只能关注当前及之前的位置,从而确保每个词元只受自己和之前词元的影响。只有输入序列中的最后一个词元累积了最多的信息,因为它是唯一一个可以访问之前所有数据的词元。因此,在垃圾消息分类任务中,我们在微调过程中会关注这个最后的词元。因此将最后的词元转换为类别标签进行预测,并计算模型的初始预测准确率。在下面代码输出中,我们只需关注最后一个输出词元的结果[-3.5983, 3.9902]
1 | def init_model_for_spam(): |
计算分类损失和准确率
之前我们通过将50257个输出转换为概率(利用softmax函数),然后返回最高概率的位置(利用argmax函数),来计算大语言模型生成的下一个词元的词元ID。
新的分类场景下,对应于最后一个词元的模型输出被转换为每个输入文本的概率分数。例如最后一个词元的结果[-3.5983, 3.9902]中两个值分别表示垃圾短信和正常短信的概率。
使用calc_accuracy_loader函数来确定各个数据集的分类准确率。我们用10个批次的数据进行估计以提高效率。
1 | # 计算每一个数据集的准确率 |
由于还没任何训练,所以对所有数据集的每个批次的8行短信输入(每行输入120个词元),每个批次的输出为[8, 120, 2],取每行输出的最后一个词元的输出为[8, 2],每一行的结果中第一列都是负数小于第二列,所以torch.argmax输出的索引都是1,predicted_labels的值为[1, 1, 1, 1, 1, 1, 1, 1],即每一行选中的都是索引1,把它与target_batch的每一个值比较是否相同计算正确率。
由于分类准确率不是一个可微分的函数,这里我们使用交叉熵损失作为替代来最大化准确率。因此,第五章的calc_loss_batch函数保持不变,唯一的调整是专注于优化最后一个词元(model(input_batch)[:, -1, :])而不是所有词元(model(input_batch))。使用calc_loss_batch函数来计算从之前定义的数据加载器中获得的单个批次的损失。为了计算数据加载器中所有批次的损失,可以像之前一样定义calc_loss_loader函数。
训练的目标是最小化训练集损失,提高分类准确率。
1 | # calc_loss_batch函数名中增加了class,避免混淆 |
6.4 模型微调和应用
在有监督数据上微调模型
训练循环与之前章节中预训练的整体训练循环相同,唯一的区别是要计算分类准确率,而不是生成文本样本来评估模型。
一轮就是完整的遍历依次训练集,批次的数量=训练集大小/每个批次大小

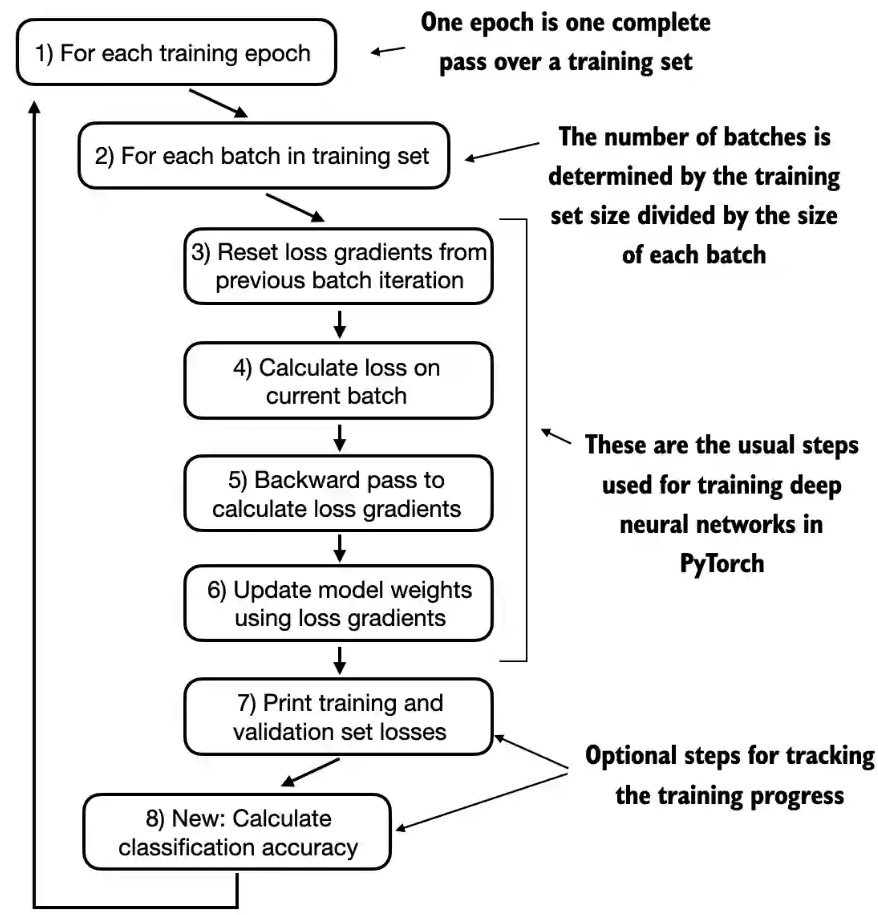
我们现在跟踪的是已经看到的训练样本数量(examples_seen),而不是词元数量,并且我们在每轮后会计算准确率,而不是打印一个文本样本。
- 训练函数
train_classifier_simple
1 | def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs, |
- 整体流程代码:
1. 加载预训练模型 1. 修改模型,以训练更新部分层的参数 1. 初始化优化器,设置训练的轮数,并使用`train_classifier_simple`函数启动训练 1. 保存新的模型参数
1 | def test_train_class_model(): |
使用matplotlib绘制趋势变化
1 | import matplotlib.pyplot as plt |

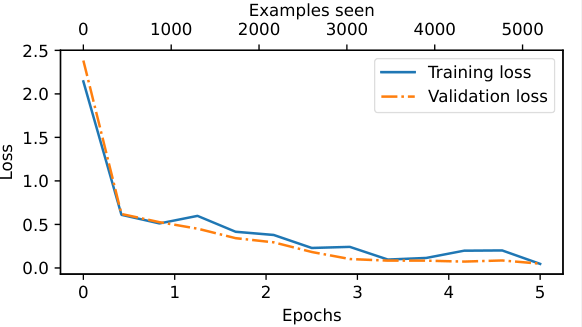
从输出结果看,第一轮后损失有明显下降趋势,可以看出模型正在有效地从训练数据中学习,几乎没有过拟合的迹象。也就是说,训练集和验证集的损失之间没有明显的差距
轮数的选择取决于数据集和任务的难度,并没有通用的解决方案,不过通常情况下,5轮是一个不错的起点。如果模型在前几轮之后出现过拟合(参见图6-16的损失曲线),则可能需要减少轮数。相反,如果趋势表明验证集损失可能随着进一步训练而改善,则应该增加轮数。在这种情况下,5轮是合理的,因为没有早期过拟合的迹象,且验证集损失接近于0。
验证集的准确率会比测试集的准确率稍高,因为模型开发过程中往往会调整超参数以提升在验证集上的性能,这可能导致模型在测试集上并不完全适用。这种情况很常见,但可以通过调整模型设置,比如增加dropout率(drop_rate)或优化器配置中的权重衰减参数(weight_decay)来尽量缩小这种差距。
使用大语言模型作为垃圾消息分类器
使用模型对输入文本进行分类的函数classify_review,其中主要是处理输入数据长度不会超过模型的上下文长度1024,以及把过短的输入补上特殊的词元,最后根据输出的分数最大值的索引决定是否是垃圾短信
1 | def classify_review(text, model, tokenizer, device, max_length=None, pad_token_id=50256): |
加载使用一个微调后的模型,这里不需要再去加载GPT2的模型参数了,只需加载之前自己微调保存后的pytorch专用的权重参数文件review_classifier.pth
1 | def test_load_class_model(): |
6.5 总结
分类微调涉及通过添加一个小型分类层来替换大语言模型的输出层
与预训练相似,微调的模型输入是将文本转换为词元ID。
在微调大语言模型之前,我们会将预训练模型加载为基础模型
分类模型的评估包括计算分类准确率(正确预测的比例或百分比)。
分类模型的微调使用与大语言模型预训练相同的交叉熵损失函数。