《从零构建大模型》
[美]塞巴斯蒂安·拉施卡
书中资料 https://github.com/rasbt/LLMs-from-scratch
附录E 使用LoRA进行参数高效微调
LoRA(低秩自适应)是应用最广泛的参数高效微调技术之一。
LoRA简介
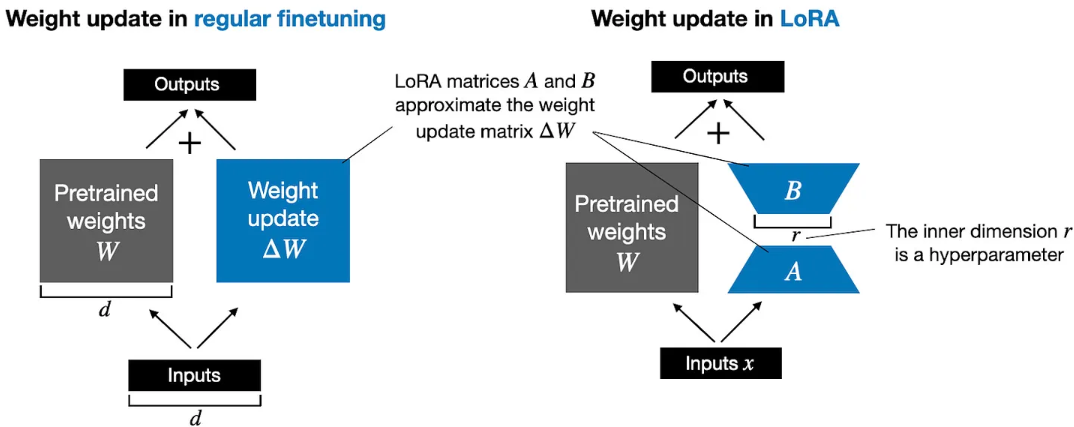
LoRA是一种通过仅调整模型权重参数的一小部分,使预训练模型更好地适应特定且通常较小的数据集的技术。“低秩”指的是将模型调整限制在总权重参数空间的较小维度子空间,从而有效捕获训练过程中对权重参数变化影响最大的方向。
对于模型的某一个层对应的巨大的权重矩阵$W$,在模型训练反向传播的过程中,通过计算最小化损失函数得到的更新权重参数矩阵$\Delta W$,最终更新后的权重为:
$$W_{\text{updated}} = W + \Delta W$$
Hu et al. 提出的LoRA提供了一个更高效的计算权重更新 $\Delta W$ 方法,通过两个小的多子矩阵相乘得到$\Delta W \approx AB$,对于最终的权重就变为:
$$W_{\text{updated}} = W + AB$$
由于矩阵乘法的分配律,它允许我们将原始权重与更新后的权重分开,而不是将它们组合在一起,即 $$x (W+\Delta W) = x W + x \Delta W$$
因此对于LoRA方法也就有:$$x (W+A B) = x W + x A B$$,可以从下图看到LoRA和全量训练的差异,同时将LoRA权重矩阵与原始模型权重分开的能力使LoRA在实践中更加有用。从而允许预训练的模型权重保持不变,并且在使用模型时可以动态地应用LoRA矩阵。这样模型定制变得更加灵活,无须存储多个完整版本的大语言模型。这降低了存储需求并提高了可扩展性,因为在为每个特定客户或应用程序进行定制时,只需调整和保存较小的LoRA矩阵即可。

准备数据集
数据准备和第6章完全相同,将数据集分成3部分:70%用于训练,10%用于验证,20%用于测试。
1 | import pandas as pd |
三个数据集分别存储到一个文件中,以后可以复用。
创建数据加载器
1 | from torch.utils.data import Dataset |
加载预训练模型
第5章一样加载预训练好的GPT2模型
1 | BASE_CONFIG = { |
设置模型进行分类
把模型的输出层替换为2维输出线性层,并输出训练前的准确率
1 | torch.manual_seed(123) |
替换模型中的线性层为LoRA
定义LoRA层
它创建了矩阵$A$ 和$B$,并设置两个超参数alpha缩放因子和rank(($r$))。该层可以接受输入并计算相应的输出。
rank作为A和B两个矩阵内部的维度,大小决定了参数总数量。例如之前权重矩阵的大小为[1024,768],它的值的个数1024*768=786432,把它用矩阵乘法分拆后为A[1024,8]乘B[8,768],其中A和B总共的参数个数(两个矩阵中值的个数)为1024*8+8*768=14336 ,Lora使用的参数数量是原来的0.018,大幅缩小了参数数量。如果rank值增加,参数量也会相应增大。
由于矩阵B的初始值被设置为0,所以初始状态下AB都是0,原来的权重和AB相加后还是之前的权重值,确保了不会改变原始权重
alpha作为低秩自适应输出的缩放因子,主要决定了适应层的输出对原始层输出的影响程度。这可以被视为调节低秩适应对层输出影响的一种方式
1 | import math |
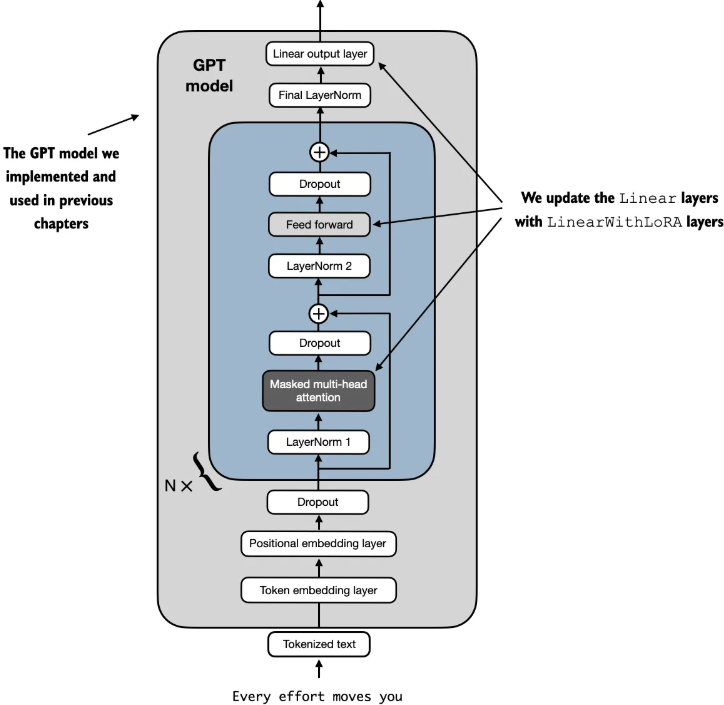
把模型中的线性层替换为LoRA层
为了整合原始线性层的权重,创建一个LinearWithLoRA层。该层利用之前实现的LoRALayer,替换神经网络中现有的线性层,比如GPTModel中的自注意力模块或前馈模块
1 | class LinearWithLoRA(torch.nn.Module): |

查看替换前后的模型参数数量变化,从124,441,346减少到2,666,528。可训练参数的数量减少到了原来的1/50。将rank和alpha设置为16是一个不错的默认选择,但增加rank参数也很常见,这反过来会增加可训练参数的数量。通常选择将alpha设置为rank的一半、两倍或等于rank的值。
1 | total_params = sum(p.numel() for p in model.parameters() if p.requires_grad) |
对模型微调完整流程
完整的流程这里分成了6步
1 | def train_sms_classify_lora(): |
最终输出:使用的时间1.3分钟比第六章全量训练的0.68分钟还要久,可能是因为其中的矩阵乘法耗时了,生成的review_lora_classifier.pth文件大小为533M
1 | Total trainable LoRA parameters: 2,666,528 |
其中替换之后的一个transformer块内包含新的LinearWithLoRA层,这些层由设置为不可训练的原始Linear层和新的LoRA层组成
1 | GPTModel( |
最后的归一化层和输出层为
1 | (final_norm): LayerNorm() |